Unravel Sensitive Data Protection
Overview
Most data sources that Unravel processes contain only metadata and performance metrics that are not considered personally identifiable information (PII). Personally identifiable information (PII) may only appear in SQL query text, which de-identifies sensitive information in query text, protects privacy, and ensures compliance as you optimize your environment.
This page shows you how to de-identify sensitive data in BigQuery using the Unravel SDP (Sensitive Data Protection) package and Google Cloud Dataflow templates. You will use pre-built pipelines and configuration files stored in Google Cloud Storage (GCS) to automate and secure data masking.
Architecture overview
The architecture for Unravel’s BigQuery data de-identification solution centers on secure, automated processing within your Google Cloud environment. User and API requests flow into Unravel’s cloud-hosted services, which manage analytics and notifications. In your own VPC, de-identification is accomplished using Dataflow pipelines and templates deployed specifically for your environment. These pipelines access BigQuery tables containing SQL query text, apply de-identification rules, and write de-identified data back to dedicated tables before any analysis by Unravel. All communication between components is secured using industry-standard authentication and encryption protocols, ensuring privacy and compliance are maintained throughout data handling and workflow operations.
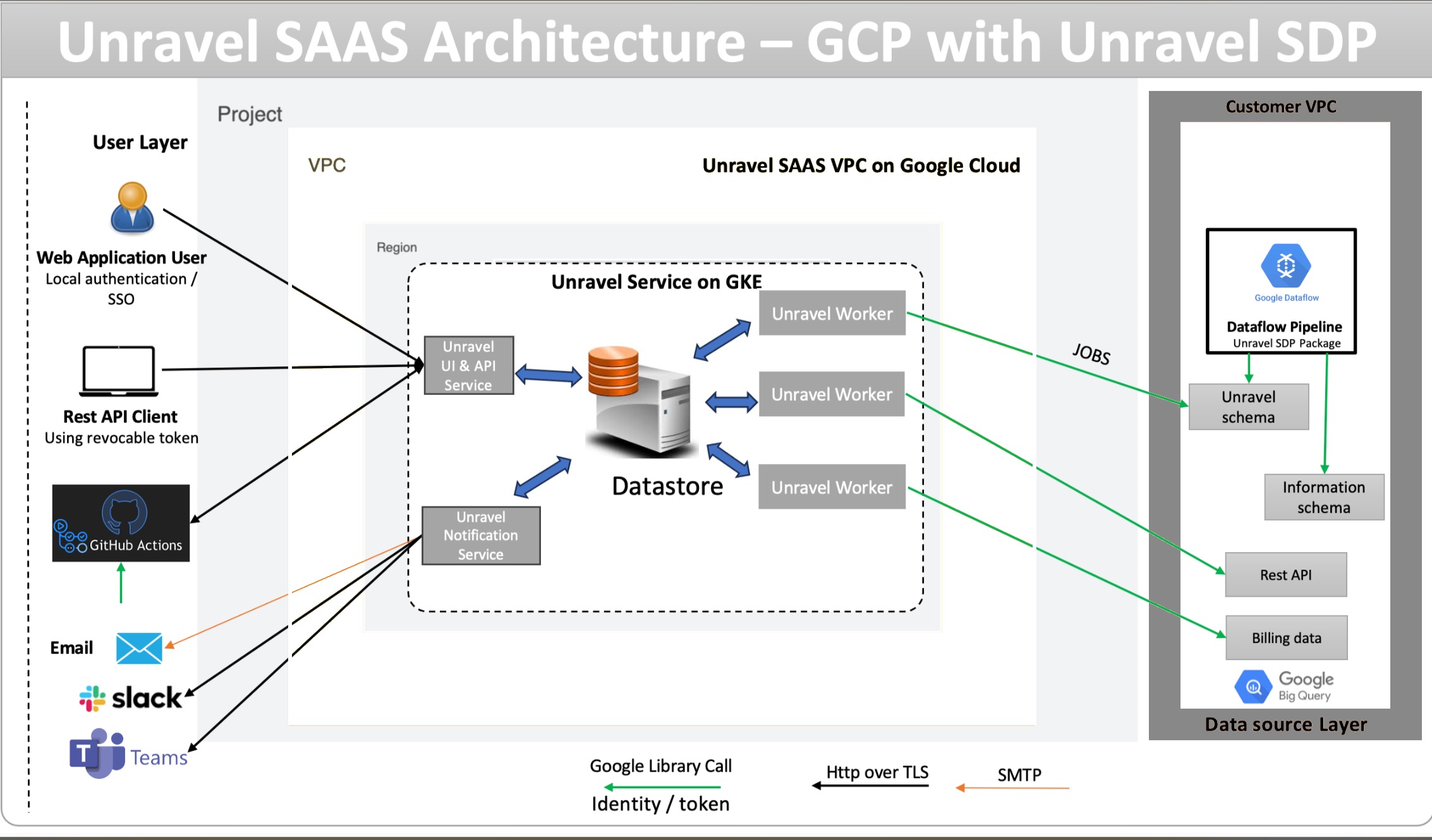
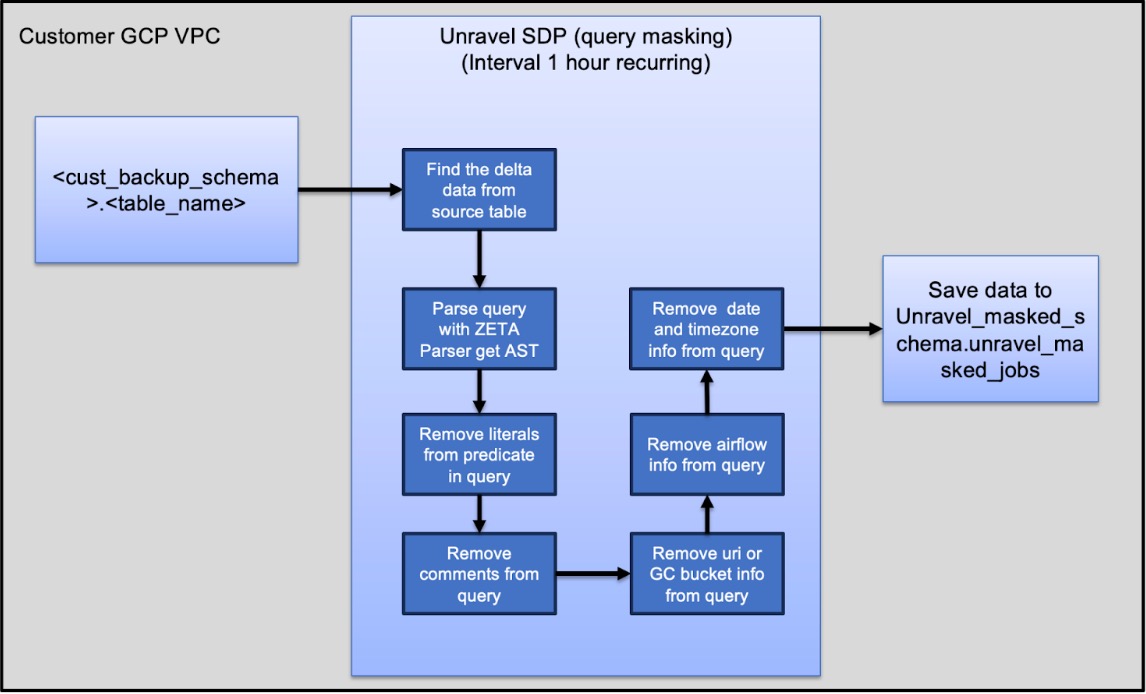
Components
This solution includes the following components:
Google Cloud Dataflow template: A pre-built pipeline that de-identifies sensitive data in BigQuery tables serverlessly.
Google Cloud Storage (GCS): A storage location for Dataflow template files and related resources.
These components work together to automate and secure the de-identification of sensitive data in your environment.
Before you begin, ensure you meet the following requirements:
Additionally, assign the following permissions to the same service account in the project from which the pipeline will retrieve data:
Role Name | Role ID | Purpose |
|---|---|---|
BigQuery Job User | roles/bigquery.jobUser | Required to initiate and monitor BigQuery jobs for data retrieval. |
BigQuery Data Editor | roles/bigquery.dataEditor | Required to read and write data in BigQuery datasets during data retrieval. |
Install the Google Cloud SDK for authentication.
Set up a dedicated Google Cloud project in BigQuery specifically for Unravel, where the Dataflow pipeline will execute.
Obtain Required IAM Roles.
The service account must be assigned the following IAM roles in the project where the pipeline will run:
Note
Creation of service account is optional.
Role Name
Role ID
Purpose
Dataflow Admin
roles/dataflow.admin
Required to To launch Dataflow jobs.
BigQuery Job User
roles/bigquery.jobUser
Required to initiate and monitor BigQuery jobs (read and write actions).
BigQuery Data Editor
roles/bigquery.dataEditor
Required to create, update, or delete BigQuery tables and datasets.
Storage Object Viewer
roles/storage.objectViewer
Required to read the Flex template from the GCS bucket.
Artifact Registry Reader
roles/artifactregistry.reader
Required to access the container image (if using Artifact Registry).
Create Required Google Cloud Storage (GCS) buckets.
Create the following bucket to store the template and temporary data used at pipeline runtime.
Staging directory: unravel-sdp/version/1.0.0/
Temporary directory: unravel-sdp/temp
Template directory: unravel-sdp/version/1.0.0/template
Prepare the following input parameters:
Parameter | Definition |
|---|---|
pollingProjectId | Specifies the Google Cloud project ID where the data pipeline will run. |
inputProjectIds | Specifies the IDs of input projects from which data will be retrieved and de-identified. |
inputTable | Specifies the fully qualified name of the source BigQuery table to be de-identified (for example, region-US.INFORMATION_SCHEMA.JOBS). |
outputTable | Specifies the fully qualified name of the BigQuery table where de-identified data will be stored. For example: proj_A.unravel_masked_schema_US.unravel_masked_jobs_US. |
location | Specifies the region of the input project. The default value is US. |
tempLocation | Specifies the Google Cloud Storage (GCS) location for storing temporary files during job execution (for example, unravel-sdp/temp). |
lookbackDays | Specifies the number of days to look back when polling data. The default value is 30. |
stagingLocation | Specifies the GCS location for staging resources (for example, unravel-sdp/version/1.0.0). |
serviceAccount | Specifies the email address of the service account that will run the data de-identification job. |
unravelSharedProject | Specifies the project ID to be shared with Unravel. |
unravelSharedDataset | Specifies the dataset name to be shared with Unravel. |
unravelSharedTempTable | The temporary table ($masked_table_prefix_temp) used to hold masked data before transfer. |
The Unravel team will provide access to a Google Cloud Storage (GCS) bucket containing the required Dataflow template and files for de-identification.
Copy the hca-202511170942-bundle.tar.gz package from the Unravel GCS bucket (unravel-dataflow-datamask-templates/hca/202511170942/) to your local directory.
Verify the file integrity by running an MD5 checksum and matching it to the hash 36739276eaf784deffb8f2f98d683a11.
Extract the verified TAR.GZ package into your target folder.
Make sure the following items are available:
unravel-sdp-template.json
unravel-sdp-pipeline
The latest Docker container image
The template JSON file is located in the templates directory of the Google Cloud Storage (GCS) bucket. The Docker container image is available in the Artifactory repository for the project.
Refer to de-identified output table creation to create the output table.
Create the Dataflow jobs using the unravel-sdp-template.json file.
Create the Dataflow pipeline using the unravel-sdp-template.json file.
The output table must conform to the following schema (matching columns, types, and nullability as provided in the input CSV):
column_name | data_type | is_nullable | column_default |
|---|---|---|---|
creation_time | TIMESTAMP | YES | NULL |
project_id | STRING | YES | NULL |
project_number | INT64 | YES | NULL |
user_email | STRING | YES | NULL |
principal_subject | STRING | YES | NULL |
job_id | STRING | YES | NULL |
job_type | STRING | YES | NULL |
statement_type | STRING | YES | NULL |
priority | STRING | YES | NULL |
start_time | TIMESTAMP | YES | NULL |
end_time | TIMESTAMP | YES | NULL |
query | STRING | YES | NULL |
state | STRING | YES | NULL |
reservation_id | STRING | YES | NULL |
total_bytes_processed | INT64 | YES | NULL |
total_slot_ms | INT64 | YES | NULL |
error_result | STRUCT<reason STRING, location STRING, debug_info STRING, message STRING> | YES | NULL |
cache_hit | BOOL | NO | NULL |
destination_table | STRUCT<project_id STRING, dataset_id STRING, table_id STRING> | NO | NULL |
referenced_tables | ARRAY<STRUCT<project_id STRING, dataset_id STRING, table_id STRING>> | NO | NULL |
labels | ARRAY<STRUCT<key STRING, value STRING>> | NO | NULL |
timeline | ARRAY<STRUCT<elapsed_ms INT64, total_slot_ms INT64, pending_units INT64, completed_units INT64, active_units INT64, estimated_runnable_units INT64>> | YES | NULL |
job_stages | ARRAY<STRUCT<name STRING, id INT64, start_ms INT64, end_ms INT64, input_stages ARRAY<INT64<, wait_ratio_avg FLOAT64, wait_ms_avg INT64, wait_ratio_max FLOAT64, wait_ms_max INT64, read_ratio_avg FLOAT64, read_ms_avg INT64, read_ratio_max FLOAT64, read_ms_max INT64, compute_ratio_avg FLOAT64, compute_ms_avg INT64, compute_ratio_max FLOAT64, compute_ms_max INT64, write_ratio_avg FLOAT64, write_ms_avg INT64, write_ratio_max FLOAT64, write_ms_max INT64, shuffle_output_bytes INT64, shuffle_output_bytes_spilled INT64, records_read INT64, records_written INT64, parallel_inputs INT64, completed_parallel_inputs INT64, status STRING, steps ARRAY<STRUCT<kind STRING, substeps ARRAY<STRING>>>, slot_ms INT64, compute_mode STRING>> | YES | NULL |
total_bytes_billed | INT64 | YES | NULL |
transaction_id | STRING | YES | NULL |
parent_job_id | STRING | YES | NULL |
session_info | STRUCT<session_id STRING> | YES | NULL |
dml_statistics | STRUCT<inserted_row_count INT64, deleted_row_count INT64, updated_row_count INT64> | YES | NULL |
total_modified_partitions | INT64 | YES | NULL |
bi_engine_statistics | STRUCT<bi_engine_mode STRING, bi_engine_reasons ARRAY<STRUCT<code STRING, message STRING>>, acceleration_mode STRING> | YES | NULL |
query_info | STRUCT<resource_warning STRING, optimization_details JSON, query_hashes STRUCT<normalized_literals STRING>, performance_insights STRUCT<avg_previous_execution_ms INT64, stage_performance_standalone_insights ARRAY<STRUCT<stage_id INT64, slot_contention BOOL, insufficient_shuffle_quota BOOL, bi_engine_reasons ARRAY<STRUCT<code STRING, message STRING>>, high_cardinality_joins ARRAY<STRUCT<left_rows INT64, right_rows INT64, output_rows INT64, step_index INT64>>, partition_skew STRUCT<skew_sources ARRAY<STRUCT<stage_id INT64>>>>>, stage_performance_change_insights ARRAY<STRUCT<stage_id INT64, input_data_change STRUCT<records_read_diff_percentage FLOAT64>>>>>, | YES | NULL |
transferred_bytes | INT64 | YES | NULL |
materialized_view_statistics | STRUCT<materialized_view ARRAY<STRUCT<table_reference STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, chosen BOOL, estimated_bytes_saved INT64, rejected_reason STRING>>>, | YES | NULL |
edition | STRING | YES | NULL |
job_creation_reason | STRUCT<code STRING> | YES | NULL |
continuous_query_info | STRUCT<output_watermark TIMESTAMP> | YES | NULL |
continuous | BOOL | YES | NULL |
query_dialect | STRING | YES | NULL |
metadata_cache_statistics | STRUCT<table_metadata_cache_usage ARRAY<STRUCT<table_reference STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, unused_reason STRING, explanation STRING, staleness_seconds INT64>>> | YES | NULL |
search_statistics | STRUCT<index_usage_mode STRING, index_unused_reasons ARRAY<STRUCT<code STRING, message STRING, base_table STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, index_name STRING>>, index_pruning_stats ARRAY<STRUCT<base_table STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, pre_index_pruning_parallel_input_count INT64, post_index_pruning_parallel_input_count INT64, index_id STRING>>> | YES | NULL |
vector_search_statistics | STRUCT<index_usage_mode STRING, index_unused_reasons ARRAY<STRUCT<code STRING, message STRING, base_table STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, index_name STRING>>, stored_columns_usages ARRAY<STRUCT<is_query_accelerated BOOL, base_table STRUCT<project_id STRING, dataset_id STRING, table_id STRING>, stored_columns_unused_reasons ARRAY<STRUCT<code STRING, message STRING, uncovered_columns ARRAY<STRING>>>>>> | ||
region | STRING | YES | NULL |
masked_status | STRING | YES | NULL |
masked_at | TIMESTAMP | YES | NULL |
Download the package from the GCS bucket.
Run the following command to copy the package to your local machine:
gcloud storage cp gs://unravel-dataflow-datamask-templates/hca/202511170942/hca-202511170942-bundle.tar.gz /path/to/local/folder/
Verify the integrity of the package.
Perform an MD5 checksum verification before extracting or using the file:
md5sum hca-202511170942-bundle.tar.gz --> 36739276eaf784deffb8f2f98d683a11
Extract the package.
Untar the .tar.gz file to a target folder:
tar -xvzf hca-202511170942-bundle.tar.gz -C /path/to/target/folder/
Review extracted files.
The SDP package includes:
A JSON file – the Dataflow pipeline template (for example, hca_pipeline.json)
A TAR file – the Docker image archive (for example, hca-202511170942-image.tar)
Load the Docker image.
Import the extracted image into your Docker environment:
docker load -i <path_to_target_folder>/hca-202511170942-image.tar
Authenticate Docker with Google Artifact Registry.
gcloud auth configure-docker <region>-docker.pkg.dev
Tag the Docker image.
Assign a tag consistent with your Artifact Registry repository:
docker tag us-central1-docker.pkg.dev/unravel-customer-usecases/unravel-dataflow-repo/hca/unravel-sdp-pipeline:202511170942 \ <region>-docker.pkg.dev/<project_id>/<repository>/hca/unravel-sdp-pipeline:202511170942
Push the image to the Artifact Registry.
docker push <region>-docker.pkg.dev/<project_id>/<repository>/hca/unravel-sdp-pipeline:202511170942
Confirm the image upload.
gcloud artifacts docker images list <region>-docker.pkg.dev/<project_id>/<repository>
Update the image field in your template.
After making this change, the <project_id> can deploy and run the Flex Template independently of the original project.
Original:
"image": "us-central1-docker.pkg.dev/unravel-customer-usecases/unravel-dataflow-repo/hca/unravel-sdp-pipeline:202511170942"
Updated:
"image": "<region>-docker.pkg.dev/<project_id>/<repository>/hca/unravel-sdp-pipeline:202511170942"
Upload the template to your GCS bucket.
gcloud storage cp <path_to_unravel_sdp_package>/hca_pipeline.json gs://<gcs_bucket_path_to_target_folder>/
You must create a BigQuery table that will store de-identified data. BigQuery is a cloud-based data warehouse service.
Set the region variable to specify where your resources reside.
SET @@location = '<location>'; -- For example, US or us-central1
Declare variables for the dataset and table names to ensure your output is uniquely named.
DECLARE polling_project_id STRING DEFAULT '<poll-project-id>'; DECLARE region STRING DEFAULT @@location; DECLARE dataset_prefix STRING DEFAULT 'unravel_masked_schema'; DECLARE dataset_name STRING DEFAULT FORMAT('%s_%s', dataset_prefix, REPLACE(region, '-', '_')); DECLARE deidentified_table_prefix STRING DEFAULT 'unravel_masked_jobs'; DECLARE deidentified_table_name STRING DEFAULT FORMAT('%s_%s', deidentified_table_prefix, REPLACE(region, '-', '_'));Create the dataset if it does not already exist.
EXECUTE IMMEDIATE FORMAT("CREATE SCHEMA IF NOT EXISTS `%s.%s`", polling_project_id, dataset_name);Create the de-identified data table, using partitioning for efficient storage and clustering for improved performance.
EXECUTE IMMEDIATE FORMAT(""" CREATE TABLE IF NOT EXISTS `%s.%s.%s` PARTITION BY DATE(masked_at) CLUSTER BY project_id OPTIONS (partition_expiration_days = 7) AS (SELECT *, "%s" AS region, "" as masked_status, CURRENT_TIMESTAMP() as masked_at FROM `%s.region-%s.INFORMATION_SCHEMA.JOBS` WHERE 1 = 0) """, polling_project_id, dataset_name, deidentified_table_name, region, polling_project_id, region);Create a temporary table to store the de-identified data, which will be cleared in the next run.
EXECUTE IMMEDIATE FORMAT( "CREATE TABLE IF NOT EXISTS `%s.%s.%s` (job_id STRING, query STRING, masked_status STRING, masked_at TIMESTAMP)", polling_project_id, dataset_name, FORMAT('%s_%s', deidentified_table_prefix, "temp") );
Follow these steps to configure a Dataflow Flex Template job:
Provide Basic Pipeline Details
Specify a job name that is descriptive and unique.
Choose the region where the job will run.
From the Dataflow templates list, select Custom Template.
Provide the Cloud Storage (GCS) path to the JSON file that defines the JOB template.
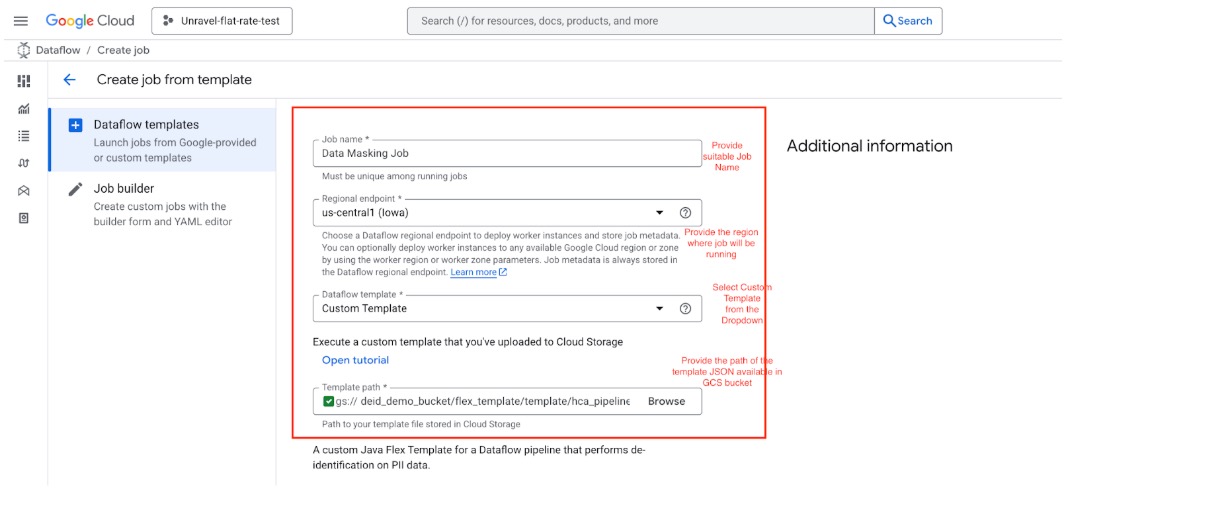
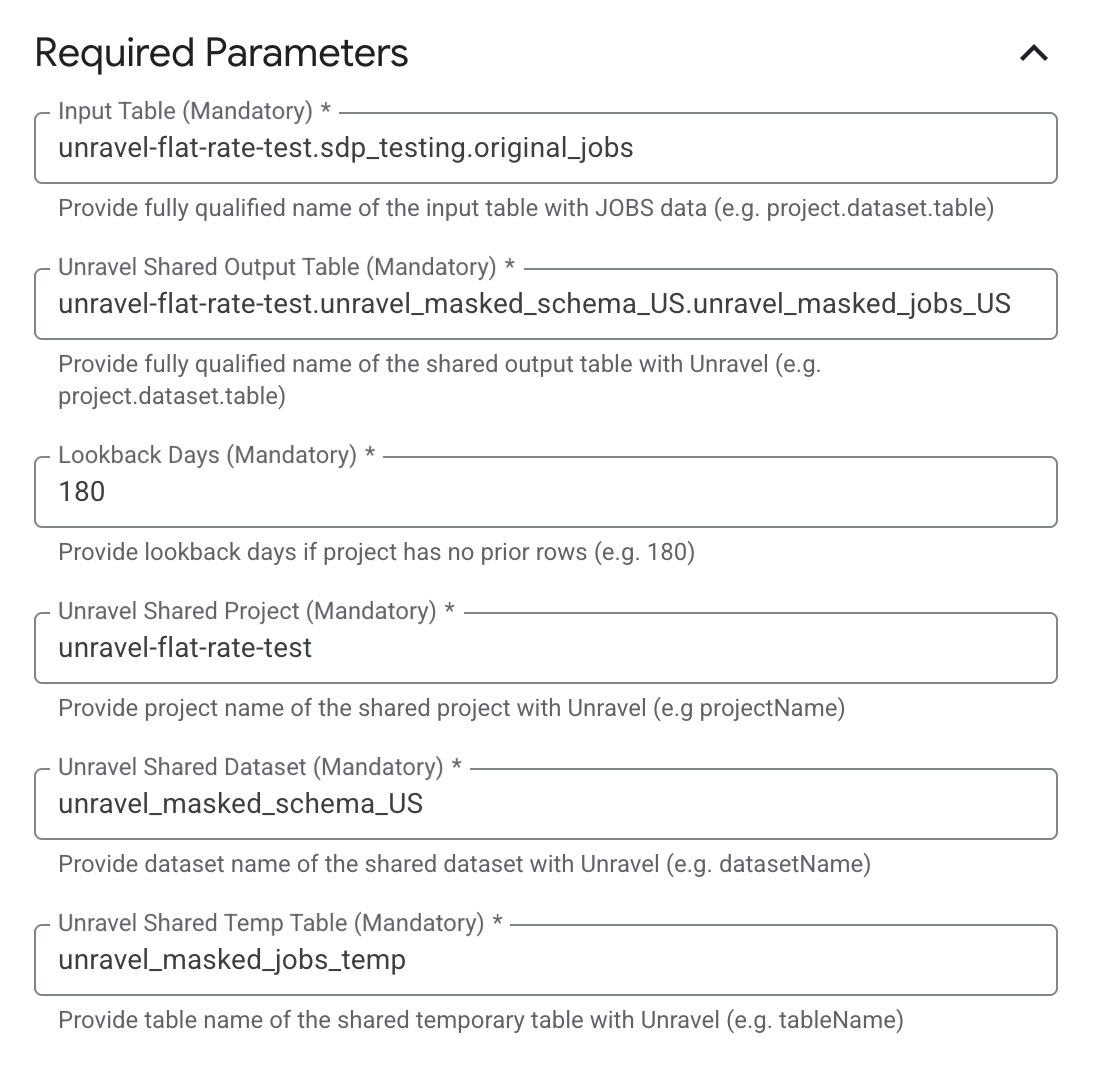
Specify Required Input Parameters
Under Required Parameters, enter the following details:
Input Table: A comma-separated list of dataset.table names, for example, project.dataset.table.
Output Table: The BigQuery table in the format project.dataset.table.
Lookback Days: The number of lookback days if the project has no prior rows.
Unravel Shared Project: The name of the shared project with Unravel.
Unravel Shared Dataset: The dataset name of the shared dataset with Unravel.
Unravel Shared Temp Table: The name of the shared temporary table with Unravel.
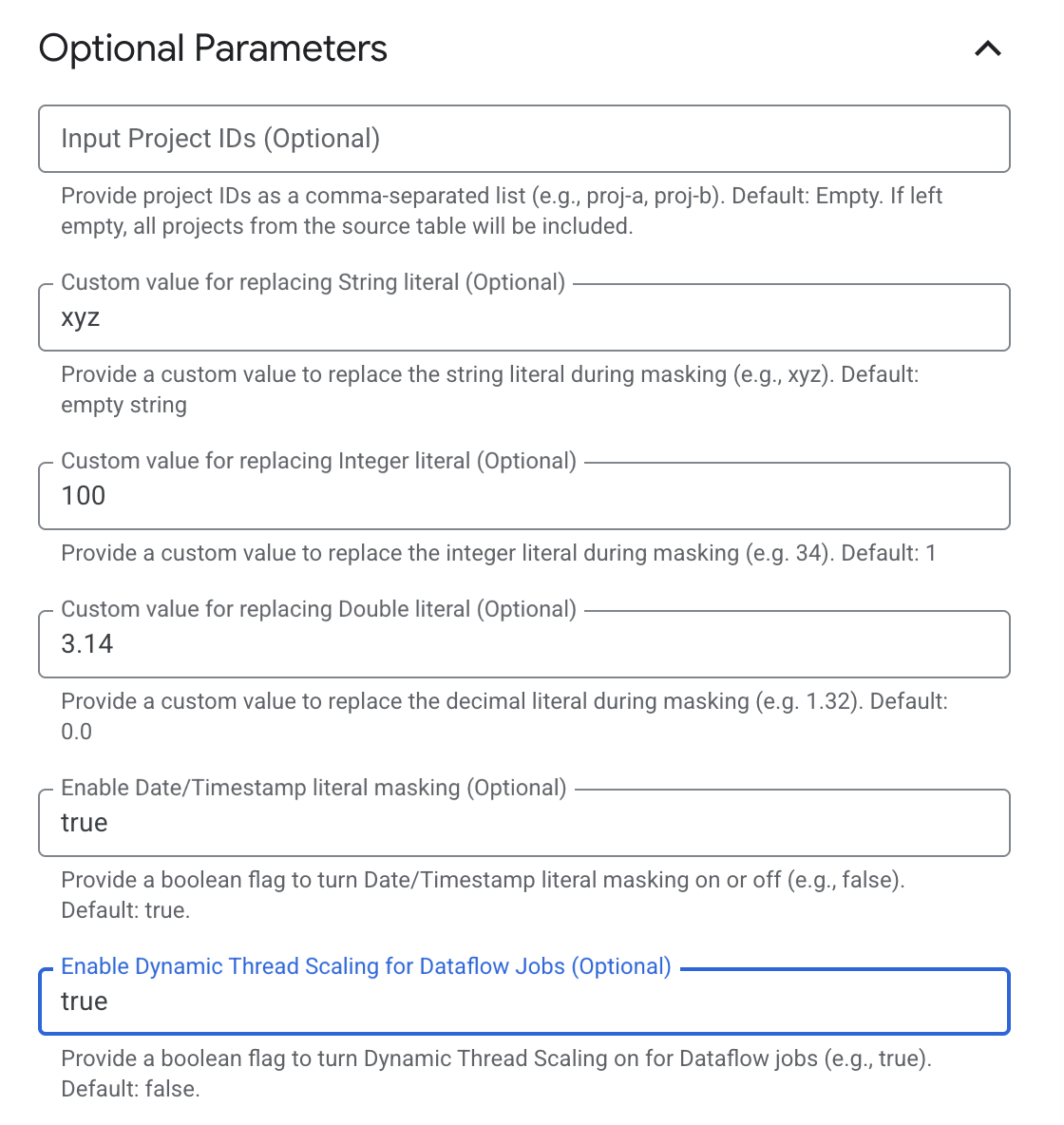
Configure Optional Parameters
Expand the Optional Parameters section.
Under Optional Parameters, enter the following details:
Input Project IDs: Enter project IDs as a comma-separated list, such as proj-a, proj-b. Leave the field empty to include all projects from the source table.
Custom value for replacing String literal: Enter the value to use for replacing string literals during masking, such as xyz. Leave the field empty to use an empty string.
Custom value for replacing Integer literal: Enter the value to use for replacing integer literals during masking, such as 34. The default value is 1.
Custom value for replacing Double literal: Enter the value to use for replacing decimal literals during masking, such as 1.32. The default value is 0.0.
Enable Date/Timestamp literal masking: Select true to mask date and timestamp literals during processing. Select false to turn off masking. The default setting is true.
Enable Dynamic Thread Scaling for Dataflow Jobs: Select true to turn on Dynamic Thread Scaling for Dataflow jobs. Select false to turn off Dynamic Thread Scaling. The default setting is false.
From the Service account email dropdown list, select the appropriate custom service account to run the pipeline.
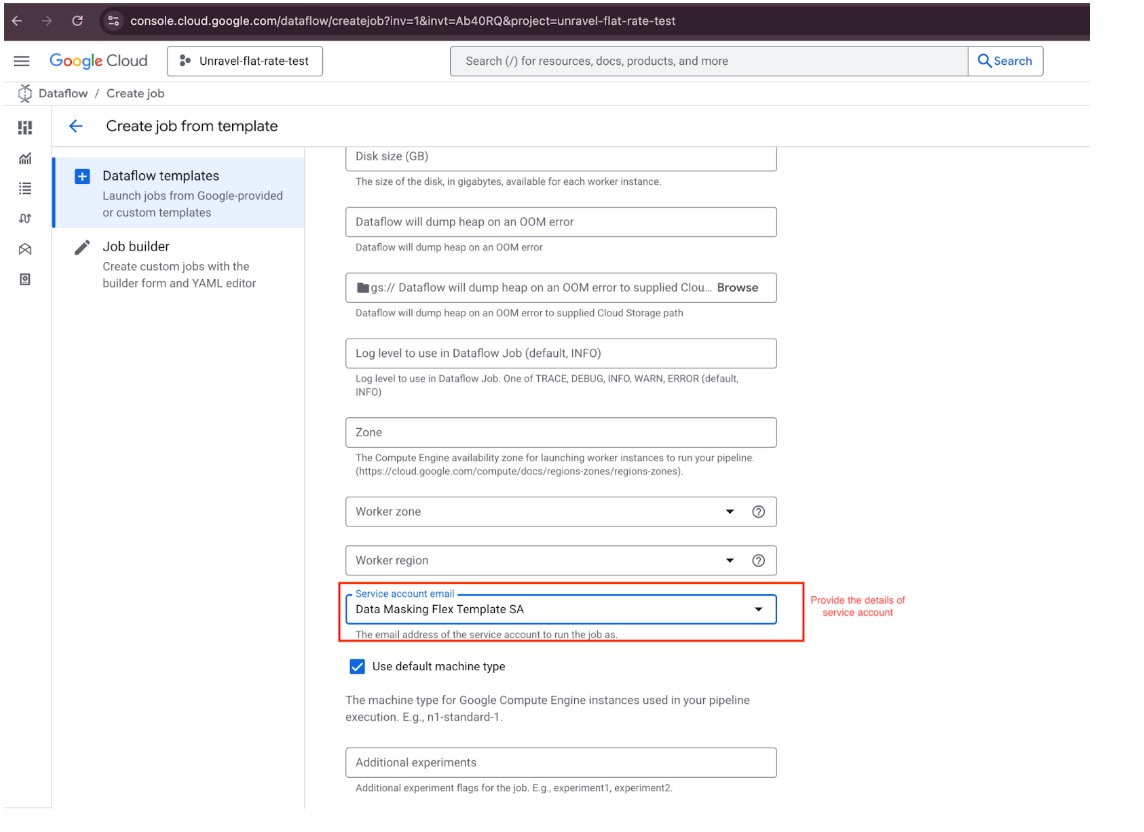
Create the Job

Review all entered information for accuracy.
Select the Run Job button to create and deploy the Dataflow Flex Template.
Follow these steps to configure a Dataflow Flex Template:
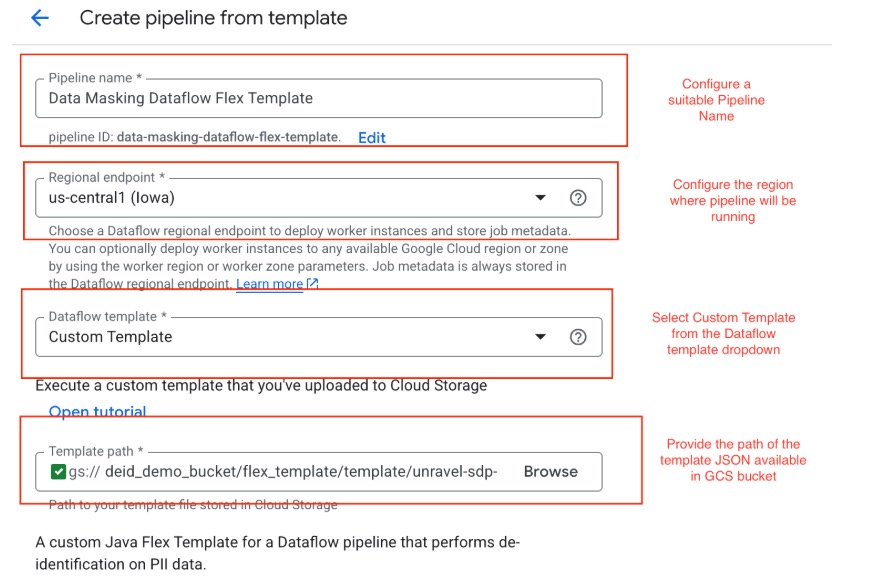
Provide Basic Pipeline Details
Specify a pipeline name that is descriptive and unique.
Choose the region where the pipeline will run.
From the Dataflow templates list, select Custom Template.
Provide the Cloud Storage (GCS) path to the JSON file that defines the pipeline template.
For example: gs://deid_demo_bucket/flex_template/template/unravel-sdp-template.json
Define the Pipeline Type and Schedule
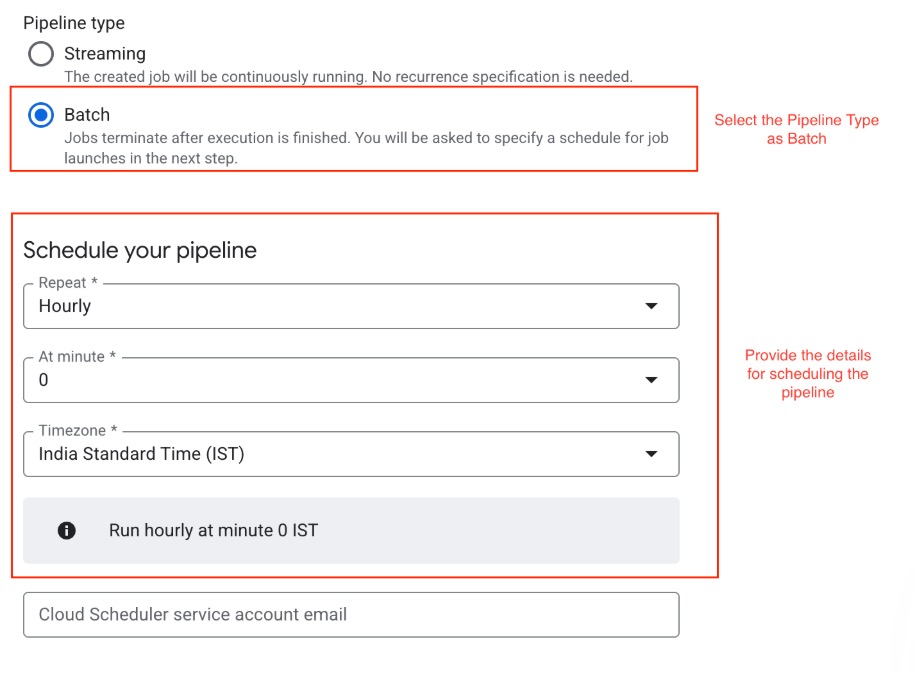
Under Pipeline type, select Batch
Configure the schedule settings for the batch job:
Repeat: Choose Hourly
At minute: Enter 0
Timezone: Select India Standard Time (IST)
Provide the Cloud Scheduler service account email to authorize scheduled runs.
Specify Required Input Parameters
Under Required Parameters, enter the following details:
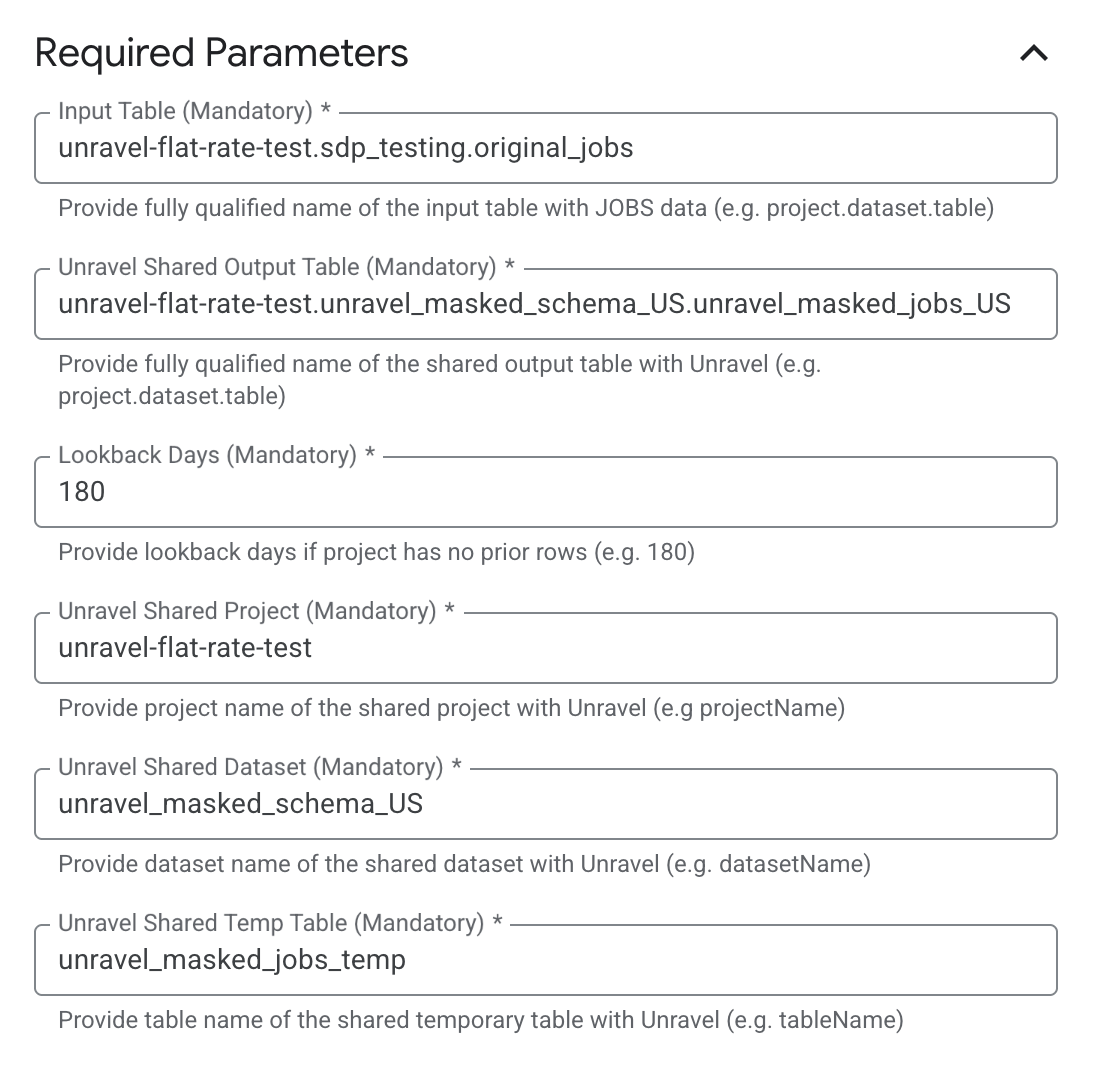
Input Table: A comma-separated list of dataset.table names, for example, project.dataset.table.
Output Table: The BigQuery table in the format project.dataset.table.
Lookback Days: The number of lookback days if the project has no prior rows.
Unravel Shared Project: The name of the shared project with Unravel.
Unravel Shared Dataset: The dataset name of the shared dataset with Unravel.
Unravel Shared Temp Table: The name of the shared temporary table with Unravel.
Configure Optional Parameters
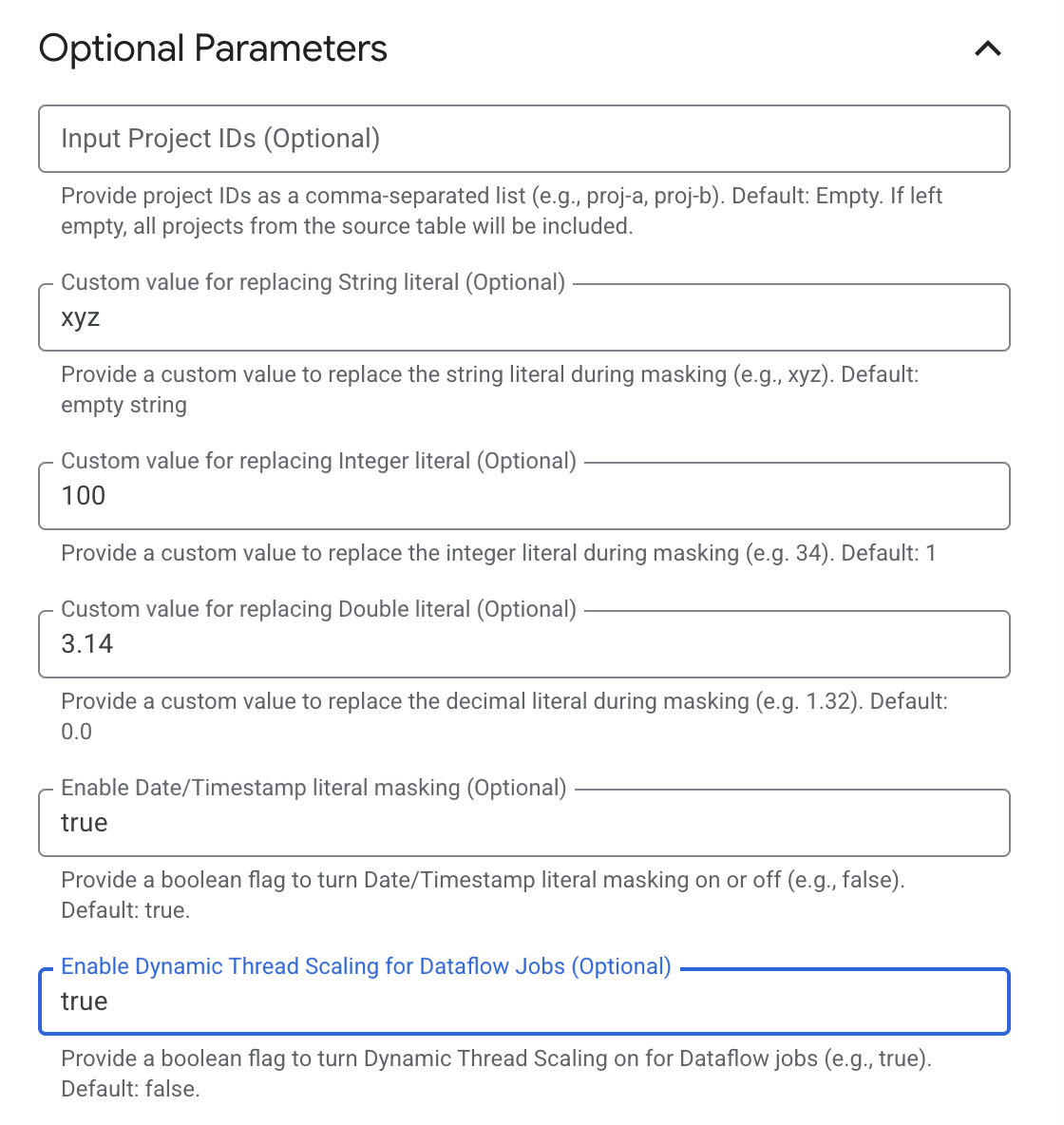
Expand the Optional Parameters section.
Under Optional Parameters, enter the following details:
Input Project IDs: Enter project IDs as a comma-separated list, such as proj-a, proj-b. Leave the field empty to include all projects from the source table.
Custom value for replacing String literal: Enter the value to use for replacing string literals during masking, such as xyz. Leave the field empty to use an empty string.
Custom value for replacing Integer literal: Enter the value to use for replacing integer literals during masking, such as 34. The default value is 1.
Custom value for replacing Double literal: Enter the value to use for replacing decimal literals during masking, such as 1.32. The default value is 0.0.
Enable Date/Timestamp literal masking: Select true to mask date and timestamp literals during processing. Select false to turn off masking. The default setting is true.
Enable Dynamic Thread Scaling for Dataflow Jobs: Select true to turn on Dynamic Thread Scaling for Dataflow jobs. Select false to turn off Dynamic Thread Scaling. The default setting is false.
From the Service account email dropdown list, select the appropriate custom service account to run the pipeline.

Create the Pipeline
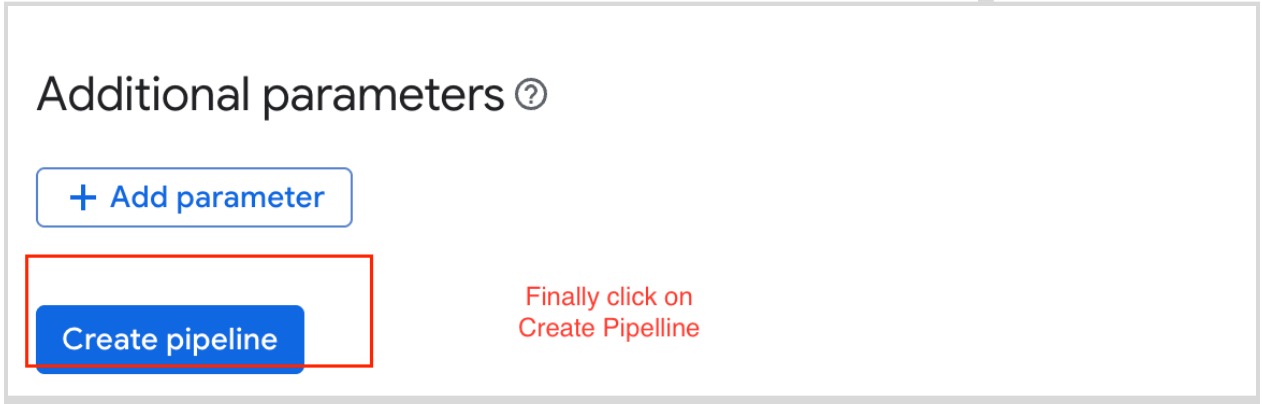
Review all entered information for accuracy.
Select the Create Pipeline button to create and deploy the Dataflow Flex Template.
Create a Custom Service Account
Note
Note: These steps are optional. Follow them only if you need a custom service account for your pipeline requirements.
Additionally, assign the following permissions to the same service account for the project from which the pipeline will retrieve data:
Navigate to Service Accounts.
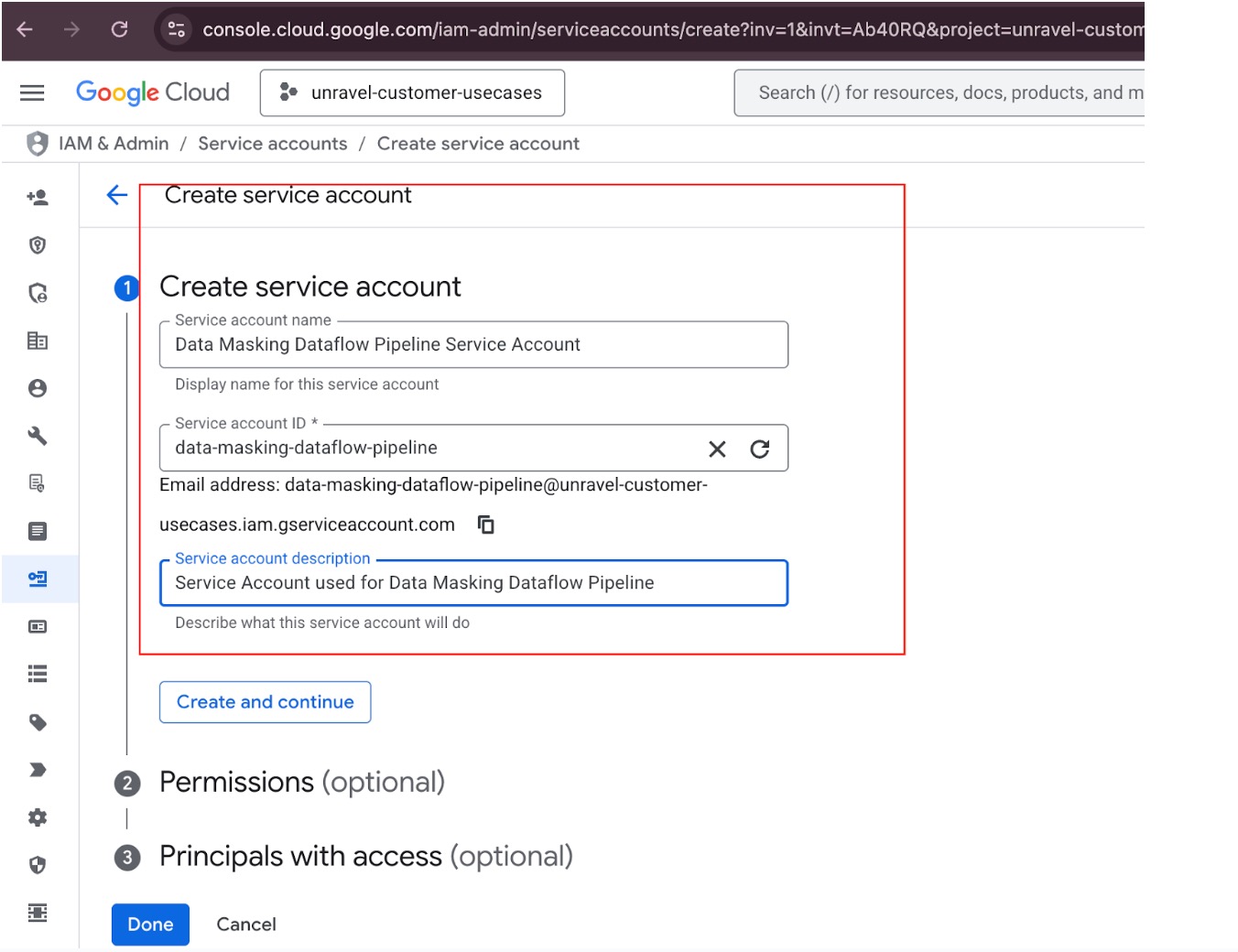
Go to the Google Cloud Console.
Select your project.
Open the navigation menu and choose "IAM & Admin," then select "Service Accounts."
Create Service Account.
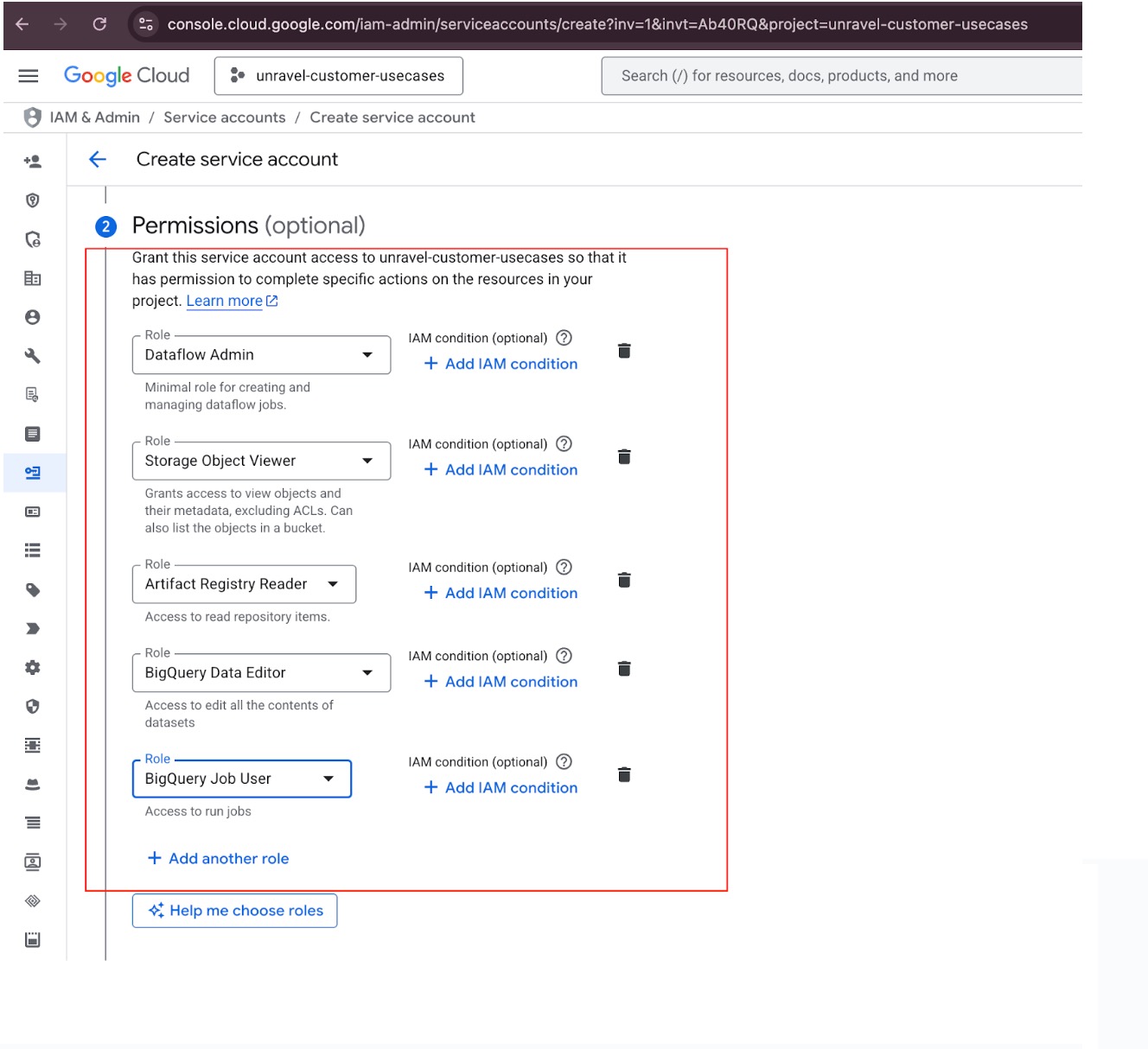
Click the "Create Service Account" button.
Enter the required information:
Service Account Name: For example, "pipeline-execution-sa."
Service Account ID: For example, "pipeline-execution-sa."
Service Account Description: For example, "Custom service account for Dataflow pipeline execution."
Click "Create and Continue."
Assign IAM Roles for Pipeline Execution.
Assign these IAM roles to the service account in the project where the pipeline will run:
Assign Roles for Data Retrieval.
Role Name
Role ID
Purpose
Dataflow Admin
roles/dataflow.admin
Required to To launch Dataflow jobs.
BigQuery Job User
roles/bigquery.jobUser
Required to initiate and monitor BigQuery jobs (read and write actions).
BigQuery Data Editor
roles/bigquery.dataEditor
Required to create, update, or delete BigQuery tables and datasets.
Storage Object Viewer
roles/storage.objectViewer
Required to read the Flex template from the GCS bucket.
Artifact Registry Reader
roles/artifactregistry.reader
Required to access the container image (if using Artifact Registry).
Role Name
Role ID
Purpose
BigQuery Job User
roles/bigquery.jobUser
Required to initiate and monitor BigQuery jobs for data retrieval.
BigQuery Data Editor
roles/bigquery.dataEditor
Required to read and write data in BigQuery datasets during data retrieval.
Complete Creation.
In the BigQuery console, go to the output table you specified as a parameter when you ran the pipeline.
Select Preview to view and validate the de-identified data.
To verify the contents of the de-identified table, run the following query:
SELECT count(1) FROM <polling_project_id>.unravel_masked_schema_US.unravel_masked_jobs_US WHERE masked_at = <date>;
Replace <polling_project_id> with your project ID and <date> with the desired timestamp.
This query returns all records from the de-identified output table that were processed at the specified time. Use it to confirm that sensitive query text has been de-identified while all other columns and the table structure remain unchanged.
The data de-identification solution uses several Google Cloud services. Costs vary by usage. The table below summarizes typical expenses.
Service | Description | Example cost |
|---|---|---|
BigQuery operations | Query processing | About $40 per 100M+ records per run. |
BigQuery storage | Storing de-identified data | About $0.02 per GB per month. 90 GB of data is about $1.80 per month |
Temporary tables | Short-term storage | Usually a few dollars per month |
Note
Your actual costs depend on your usage.