Databricks workspace setup guide
This section provides instructions to connect a Databricks cluster to Unravel SaaS.
Create a Workspace token in Databricks.
Go to Workspace > Admin Console > Access Control and enable Personal Access Tokens. For more details, refer to Manage personal access tokens.
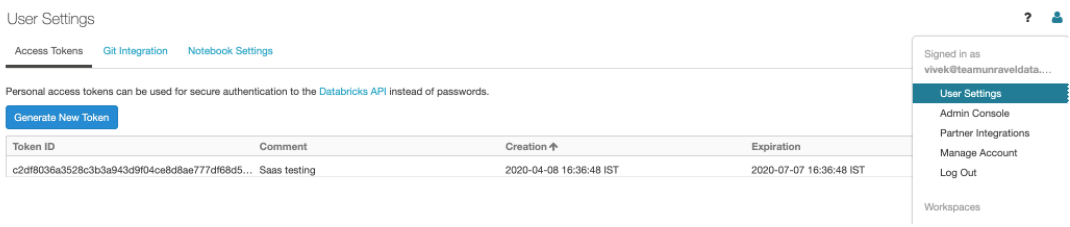
Go to Workspace > User Settings > Access Tokens and click Generate New Token. For more details, refer to Authentication using Databricks personal access tokens.

Connect Databricks cluster to Unravel.
Run the following steps to connect the Databricks cluster to Unravel.
Register workspace in Unravel.
Sign in to Unravel UI, and from the upper right, click
 > Workspaces. The Workspaces Manager page is displayed.
> Workspaces. The Workspaces Manager page is displayed.Click Add Workspace and enter the following details.
Field
Description
Workspace Id
Databricks workspace ID, which can be found in the Databricks URL.
The random numbers shown after o= in the Databricks URL become the workspace ID.
For example, in this URL:https://<databricks-instance>/?o=987654321123456, the Databricks workspace ID is the random number after o=, which is 987654321123456.
Workspace Name
Databricks workspace name. A human-readable name for the workspace. For example,
ACME-WorkspaceInstance (Region) URL
Regional URL where the Databricks workspace is deployed. Specify the complete URL. For example, https://dbc-1dbx661f-a33e.cloud.databricks.com
Tier
Select a subscription option: Standard or Premium. For Databricks Azure, you can get the pricing information from the Azure portal. For Databricks AWS, you can get detailed information about pricing tiers from Databricks AWS pricing.
Token
Use the personal access token to secure authentication to the Databricks REST APIs instead of passwords. You can generate the token from the workspace URL (Go to )
See Authentication using Databricks personal access tokens to create personal access tokens.
Note
Users with admin or non-admin roles can create personal access tokens. Non-admin users must ensure to fulfill certain requirements before creating personal access tokens.
Note
After you click Add, it takes around 2-3 minutes to register the Databricks Workspace with Unravel.
Add Unravel configuration to Databricks clusters using any of the following options:
Global init script
Global init script applies the Unravel configurations to all clusters in a workspace. Do the following to set up Unravel configuration as Global init scripts:
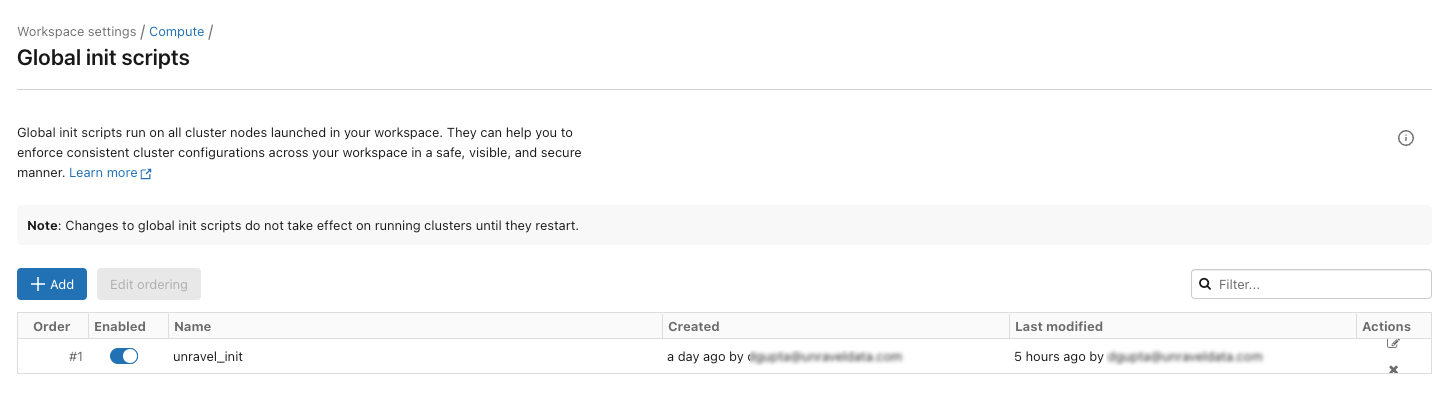
Global init is deployed automatically on the Workspace and needs to be enabled manually from the location shown in the following image:
Go to your workspace, and from the dropdown located in the upper right corner, select Admin Settings.
From Settings, click Compute and then click Manage next to Global init scripts. The Global init scripts page is shown.
Use the toggle key under the Enabled column to enable the Global init scripts.
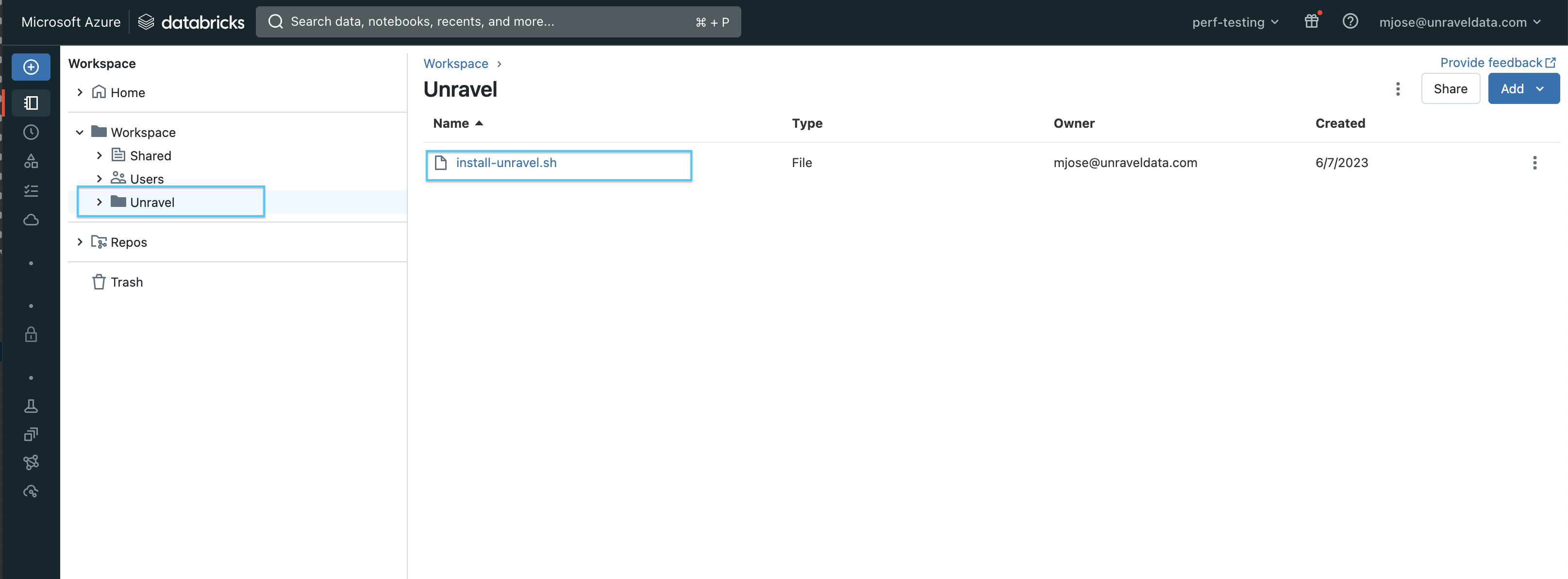
You can also find the Global initialization script in your workspace at this path: /Workspace/Unravel/install-unravel.sh
If it is not deployed automatically, you can do one of the following
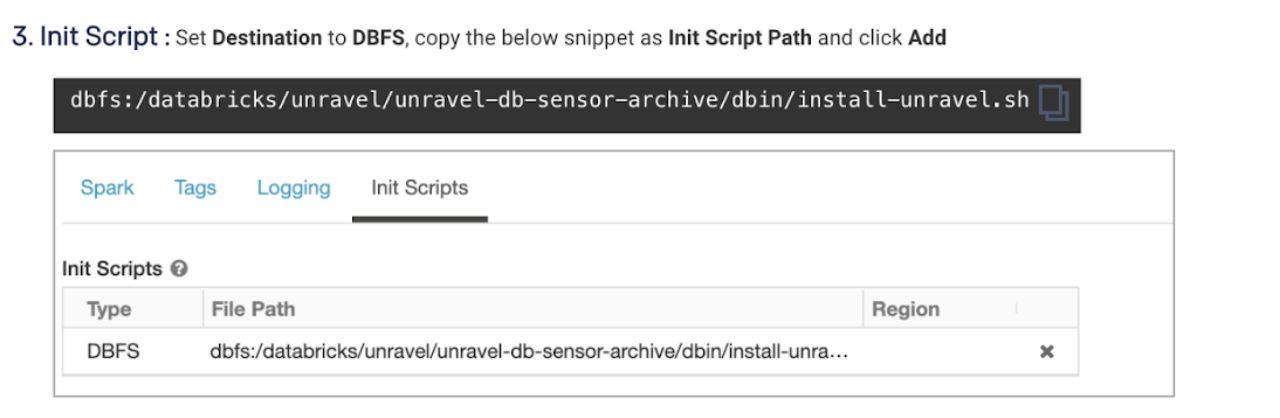
Use this script as a Cluster init script.
Add Unravel configuration to Databricks clusters using the Global init script by referring to these instructions.
Note
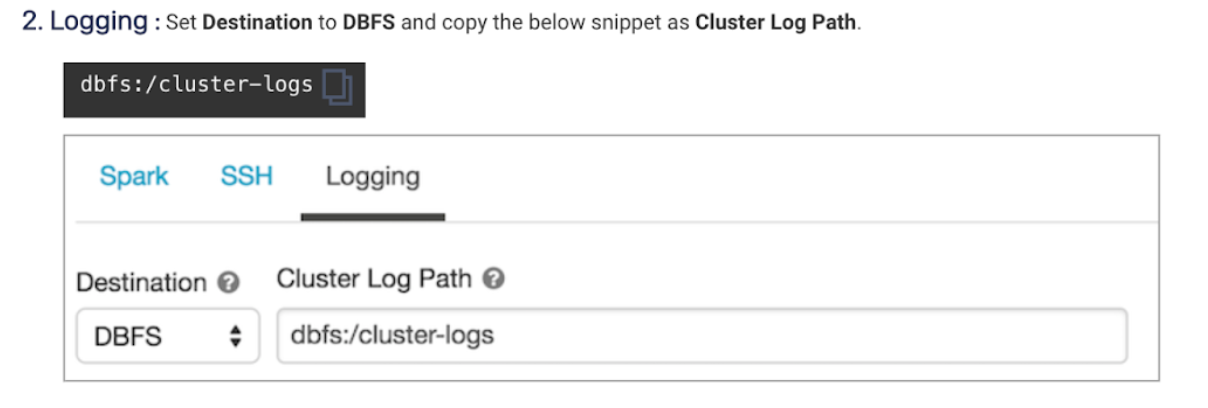
Cluster logging should be enabled at the cluster level. See Logging in Cluster init script for instructions.
Important
When you upgrade from an Unravel version below v4.7.5.0, you must disable or remove all the previously set up global init scripts (unravel_cluster_init, unravel_spark_init).
Cluster init script
The Cluster init script applies the Unravel configurations at the cluster level. To setup cluster init scripts from the cluster UI, do the following:
Go to Unravel UI, and click Manage > Workspaces.
Choose the desired workspace as the source.
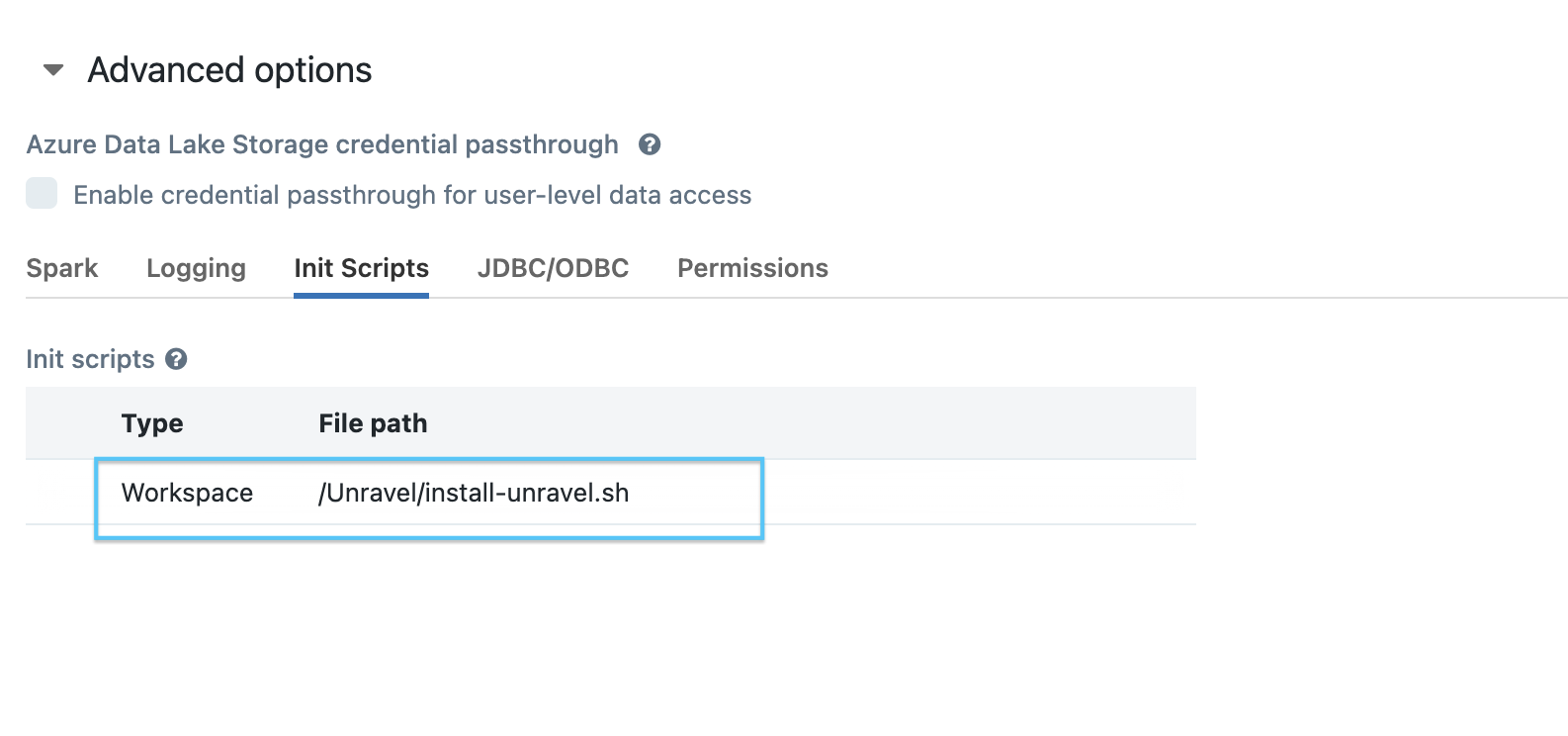
Set the path as: /unravel/install-unravel.sh.
Note
Prior to configuring the new cluster-level init script, ensure you remove any existing cluster-level init script configurations that are pointing to the DBFS location. For cluster-level init script setup, make sure to configure it using the workspace file path: /unravel/install-unravel.sh.
Note
To add Unravel configurations to job clusters via API, refer How to setup cluster init scripts via cluster API.
The Cluster init script applies the Unravel configurations at the cluster level. To setup cluster init scripts from the cluster UI, do the following:
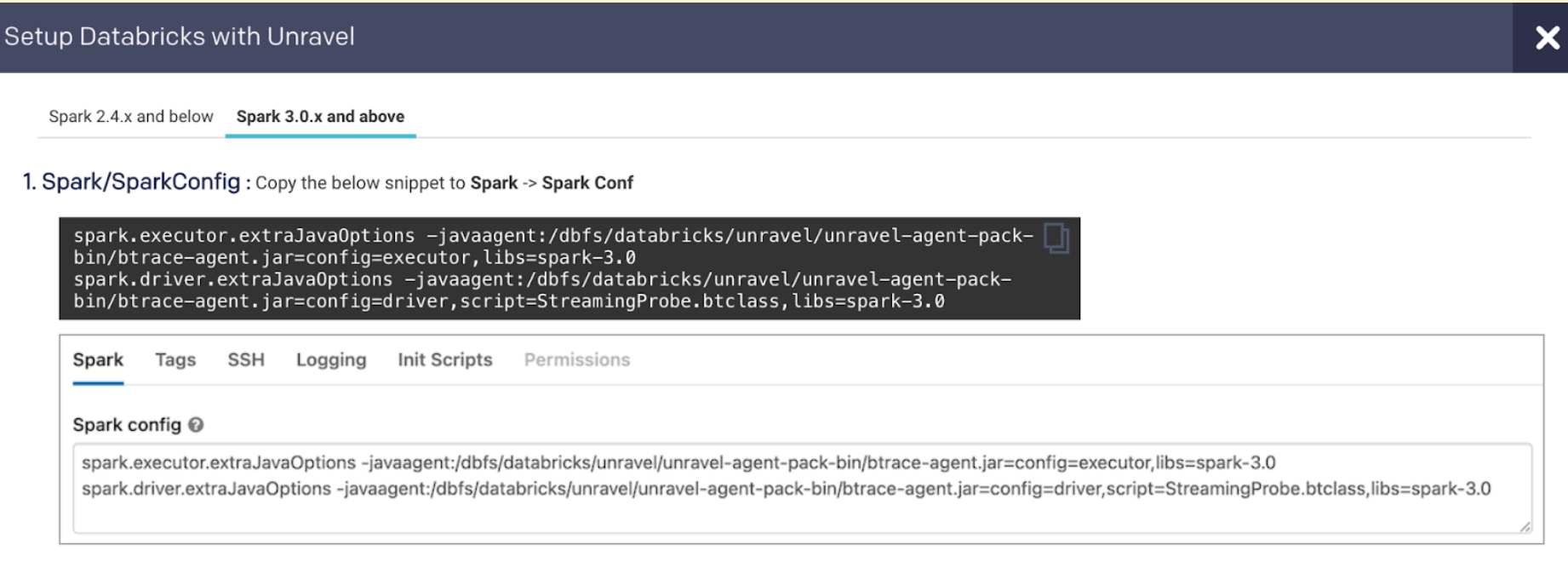
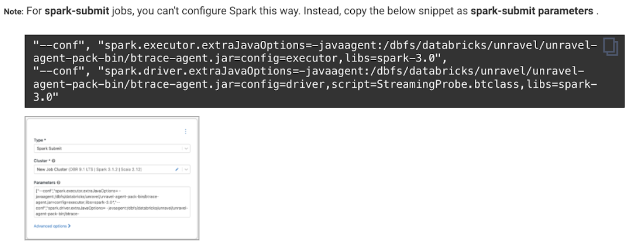
Go to Unravel UI, and click Manage > Workspaces > Cluster configuration to get the configuration details.
Follow the instructions and update each cluster (Automated /Interactive) that you want to monitor with Unravel.
Add Unravel configuration to Databricks clusters. Go to Unravel UI, and from the upper right, click Manage
> Workspaces > Cluster configuration to get the configuration details. Follow the instructions and update every cluster (Automated /Interactive) in your workspace.Tip
By default, the Ganglia metrics are enabled with Dcom.unraveldata.agent.metrics.ganglia_enabled property set to true.
Note
To add Unravel configurations to job clusters via API, refer How to setup cluster init scripts via cluster API.
Tip
The workspace setup can be done anytime and does not impact the running clusters or jobs.