Upgrading Unravel (Amazon EMR, Databricks) to 4.7.8.0
This topic provides instructions to upgrade Unravel (Amazon EMR, Databricks) to 4.7.8.0.
For Amazon EMR, the latest Unravel version you can upgrade from is v4.7.5.0.
For Databricks, the latest Unravel version you can upgrade from is v4.7.6.0.
The following upgrade paths are supported:
4.7.x.x → 4.7.8.0
4.6.1.9 → 4.7.8.0
4.6.1.8 or earlier → 4.6.1.9 → 4.7.8.0
Before you upgrade to Unravel (Cloud), do the following:
Take a backup of the data directory and the external database if you use one. To back up the data, refer to Backing up and recovering Unravel
Note
If an upgrade fails, you can roll back the upgrade to the release from which you had upgraded. For information, see Rollback after a failed upgrade. For this rollback to work, you must ensure to take a backup of the data directory and the external database before you upgrade.
Unravel requires Java Runtime Environment (JRE), and hence it is shipped with OpenJDK version 17.0.1. If you have a different version of JDK installed, you must configure Unravel to access the corresponding jre directory in that JDK. For instructions, refer to Configuring custom JDK.
Go to the Download section. The complete list of Unravel downloads is available in this section.
Download the Unravel version that you want to upgrade. The section provides the details and necessary instructions to download Unravel.
Extract the Unravel binaries of the Unravel version you want to upgrade.
tar zxf unravel-
<version>tar.gz -C</path/to/installation/directory>For example: tar zxf unravel-4.7.8.0.tar.gz -C /opt
Stop Unravel.
<Unravel installation directory>/unravel/manager stopActivate Unravel version 4.7.8.0.
<Unravel installation directory>/unravel/manager activate 4.7.8.0Set Unravel license. Changing the license is mandatory. Contact Unravel Customer Support to get a new license file.
<Unravel installation directory>/unravel/manager config license set
<path to license file>For example:
Example: /opt/unravel/manager config license set /tmp/license.txt
For more information about setting the license file, see Setting Unravel license.
Start all the services.
<unravel installation directory>/unravel/manager start
Check the status of the services.
<unravel_installation_directory>/unravel/manager report
The following service statuses are reported:
OK: Service is up and running.
Not Monitored: Service is not running. (Has stopped or has failed to start)
Initializing: Services are starting up.
Does not exist: The process unexpectedly disappeared. A restart will be attempted 10 times.
Validate the JAVA version that Unravel is using now.
Delete the previous installation directory from
unravel/versions/<THE.OLD.VERSION>.
Important
Ensure to perform the post-upgrade steps. Refer to Post upgrade steps .
Go to Unravel node and sign in as unravel user. In the case of multi-cluster, go to Unravel edge node.
Run the following command:
ps -ef | grep unravel | grep java
For example, the following output is shown:
unravel 26871 1 1 Jul05 ? 00:30:43 /tmp/jdk1.8.0_112/jre/bin/java -server -Dident=unravel_taw_1 -Dunravel.log.dir=/opt/unravel/logs -Dhadoop.version= -Djdbc.driver.jar=com.mysql.jdbc.Driver -Dhadoop.conf.dir=/etc/hadoop/conf -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dnetworkaddress.cache.ttl=30 -Dsun.net.inetaddr.ttl=30 -Xmx6g -Xms1g -Dvertx.cacheDirBase=/opt/unravel/tmp/ver
In the above example, Unravel has selected the Java version
/tmp/jdk1.8.0_112/jre/bin/java.You can further validate the Java version. For example, run the following command:
/tmp/jdk1.8.0_112/jre/bin/java -version
After you upgrade Unravel, you can optionally regroup multiple Spark worker instances for enhanced performance.
Regrouping multiple Spark worker instances for enhanced performance (Optional)
Caution
The following task requires planning and should be performed only in collaboration with Unravel support team. This is a one-time task.
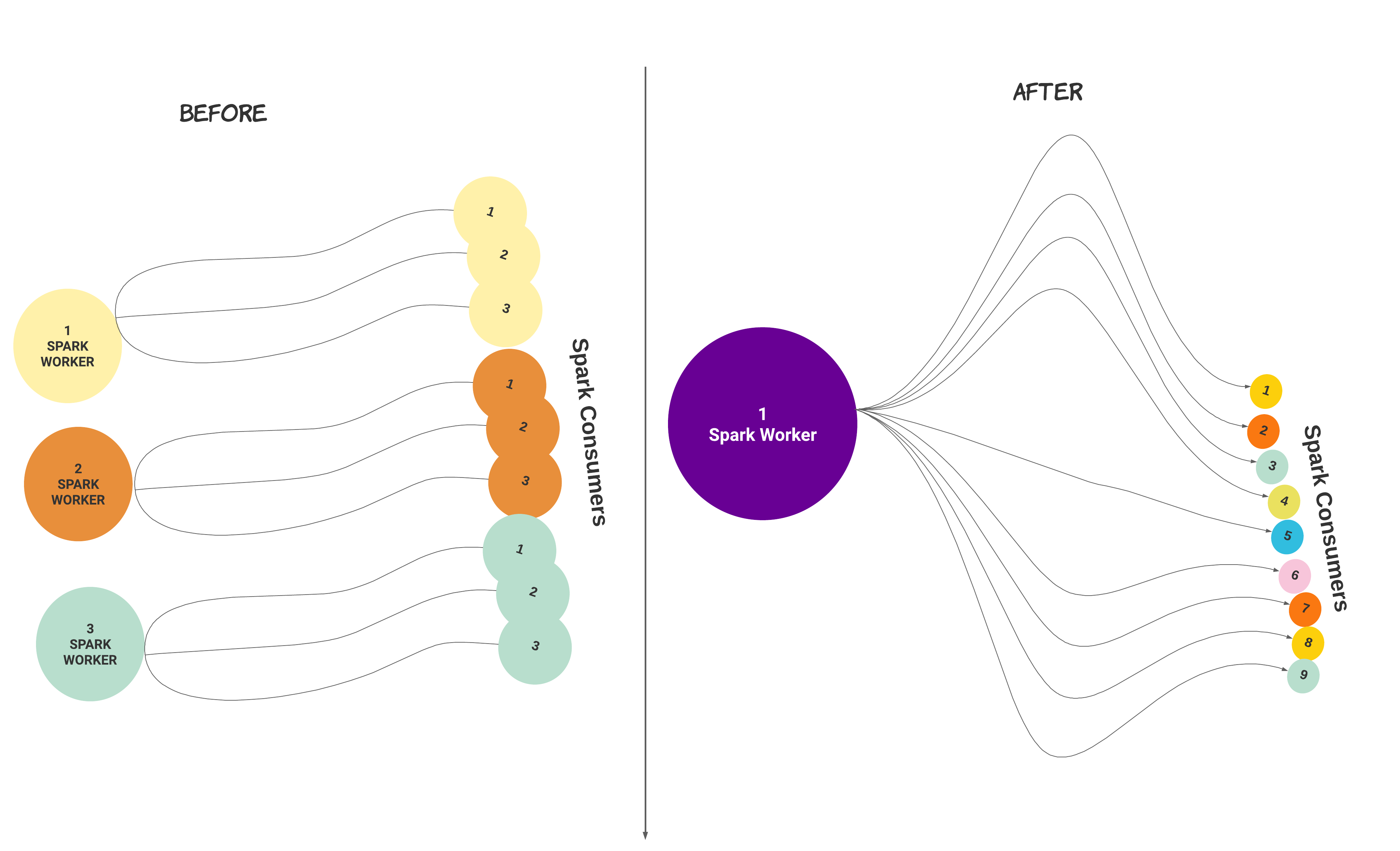
Spark worker is multi-threaded from Unravel version 4.7.8.0. After installation or upgrade, you can migrate a setup with multiple Spark worker instances with consumers to a setup with a single Spark Worker with multiple consumers.
When you run the following command, the number of Spark workers and the number of consumers configured get regrouped under a single Spark worker with an equivalent number of consumers.
In the following illustrated example, three Spark workers with three consumers each get regrouped into one Spark worker with nine consumers.
Caution
To avoid out-of-memory issues, you must review the memory configuration and ensure that you have sufficient memory.
To regroup multiple Spark worker instances with consumers, do the following:
Stop Unravel on the worker node.
/
<unravel_installation_directory>/unravel/manager stopCheck the number of Spark workers that are configured.
/
<unravel_installation_directory>/unravel/manager config worker showCheck the status of memory.
/
<unravel_installation_directory>/unravel/manager config memory showRun the following command:
<unravel_installation_directory>/unravel/manager config worker coalesce spark_workerApply the changes.
<Unravel installation directory>/unravel/manager config applyCheck the status of memory again to ensure that the total memory for the Spark worker is sufficient. If you want to set more memory per consumer, refer to Set memory for Spark worker per consumer.
/
<unravel_installation_directory>/unravel/manager config memory showStart Unravel on the Spark worker node.
/
<unravel_installation_directory>/unravel/manager start