Part 2: Connecting Unravel to a Databricks cluster
Using the Azure Databricks UI or clusters API, connect Unravel to the Databricks jobs/cluster you want Unravel to monitor:
Add a cluster node initialization script:
On the cluster configuration page, click Advanced Options.
At the bottom of the page, click the Init Scripts tab.
In the Destination drop-down, select a destination type.
Specify the path to the initialization script as
dbfs:/databricks/unravel/unravel-db-sensor-archive/dbin/install-unravel.sh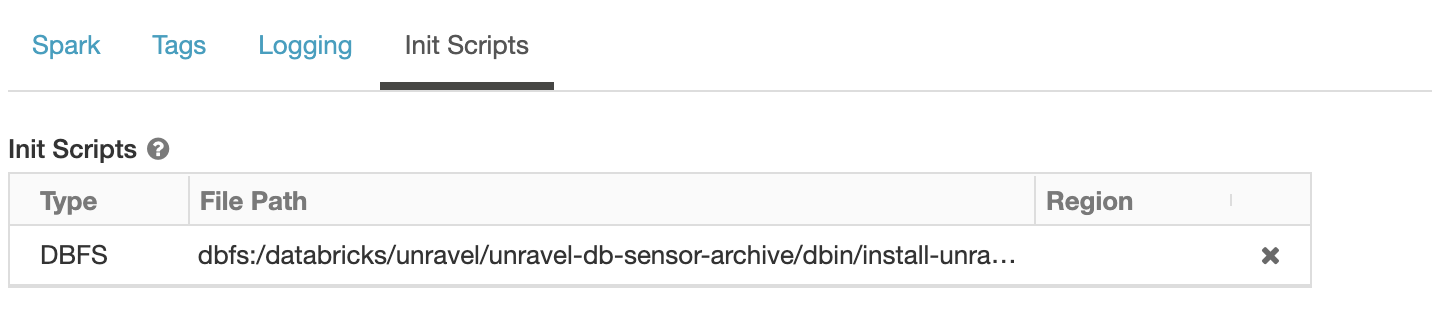
Click Add.
Configure Spark:
On the cluster configuration page, click Advanced Options.
At the bottom of the page, click the Spark tab.
Paste the snippet generated by
databricks_setup.shinto the text box.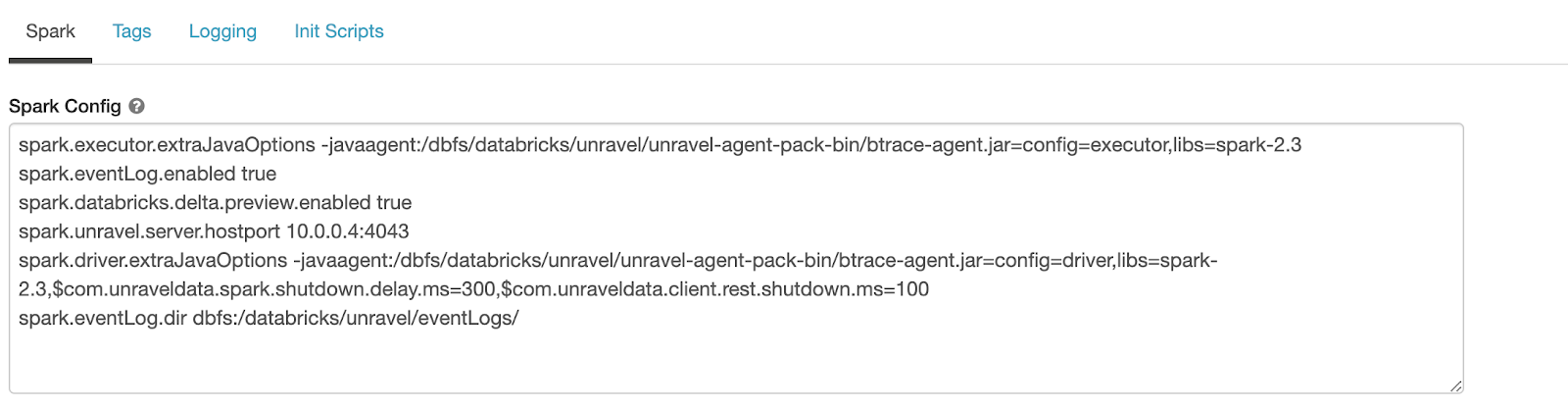
Click Add.
Note
If you submit Spark jobs through spark-submit, you can't configure Spark this way.
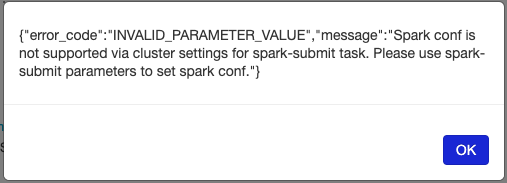
Instead, you have to use spark-submit parameters with the snippet as provided by
databricks_setup.sh.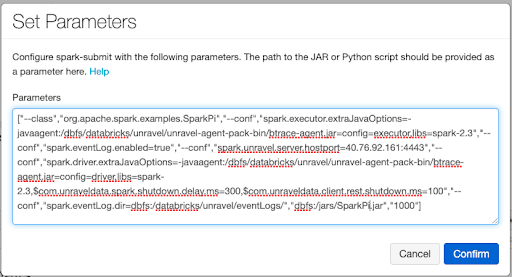
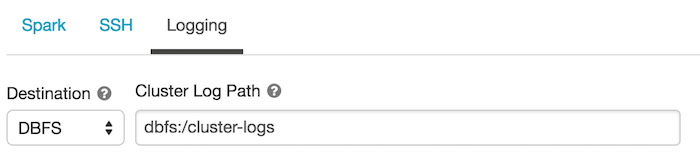
Connect to cluster logs:
To configure the log delivery location:
On the cluster configuration page, click Advanced Options.
At the bottom of the page, click the Logging tab.
Select a destination type DBFS.
Enter the cluster log path.
Next steps
Enable additional instrumentation and configure optional settings.