Using RDD caching to improve a Spark app's performance
Due to Spark’s lazy evaluation model, there are often cases where a Spark app recomputes the same RDD several times during the lifetime of the app. Spark provides a facility cache(), which when inserted into your code, caches RDDs in executor memory. This can result in improving performance and decreasing overall execution time, especially when a given RDD is re-computed multiple times over the app's lifetime.
Unravel's insights and recommendations tells you when you can take advantage of cache() to improve your app's performance.
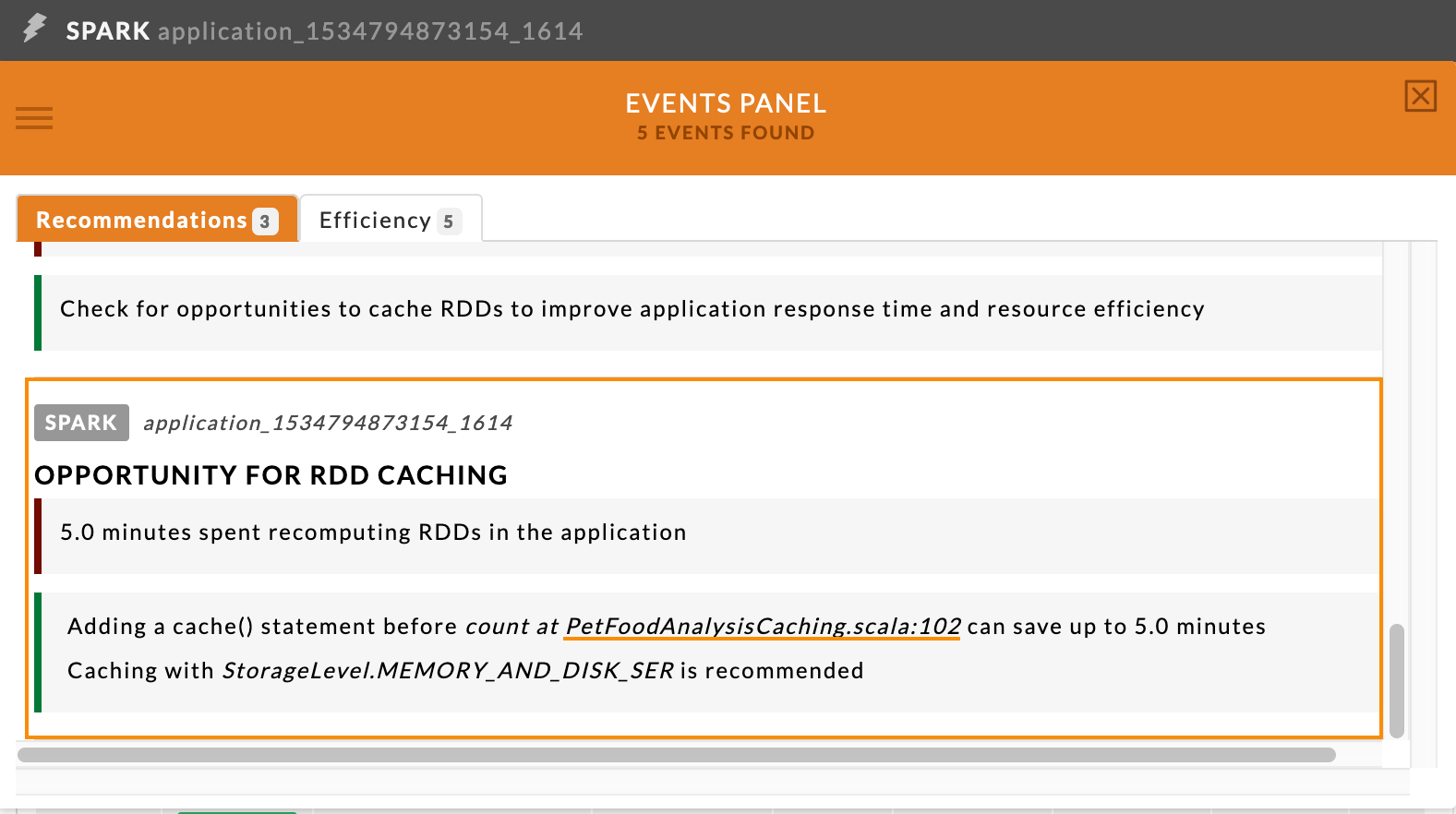 |
Above is an example, where Unravel is recommending RDD caching. But, more than that, Unravel also recommends where you should insert cache() into your code. In this case, Unravel recommends inserting it before line 102. The Spark APM than can show you the context of where in the code you should place it.
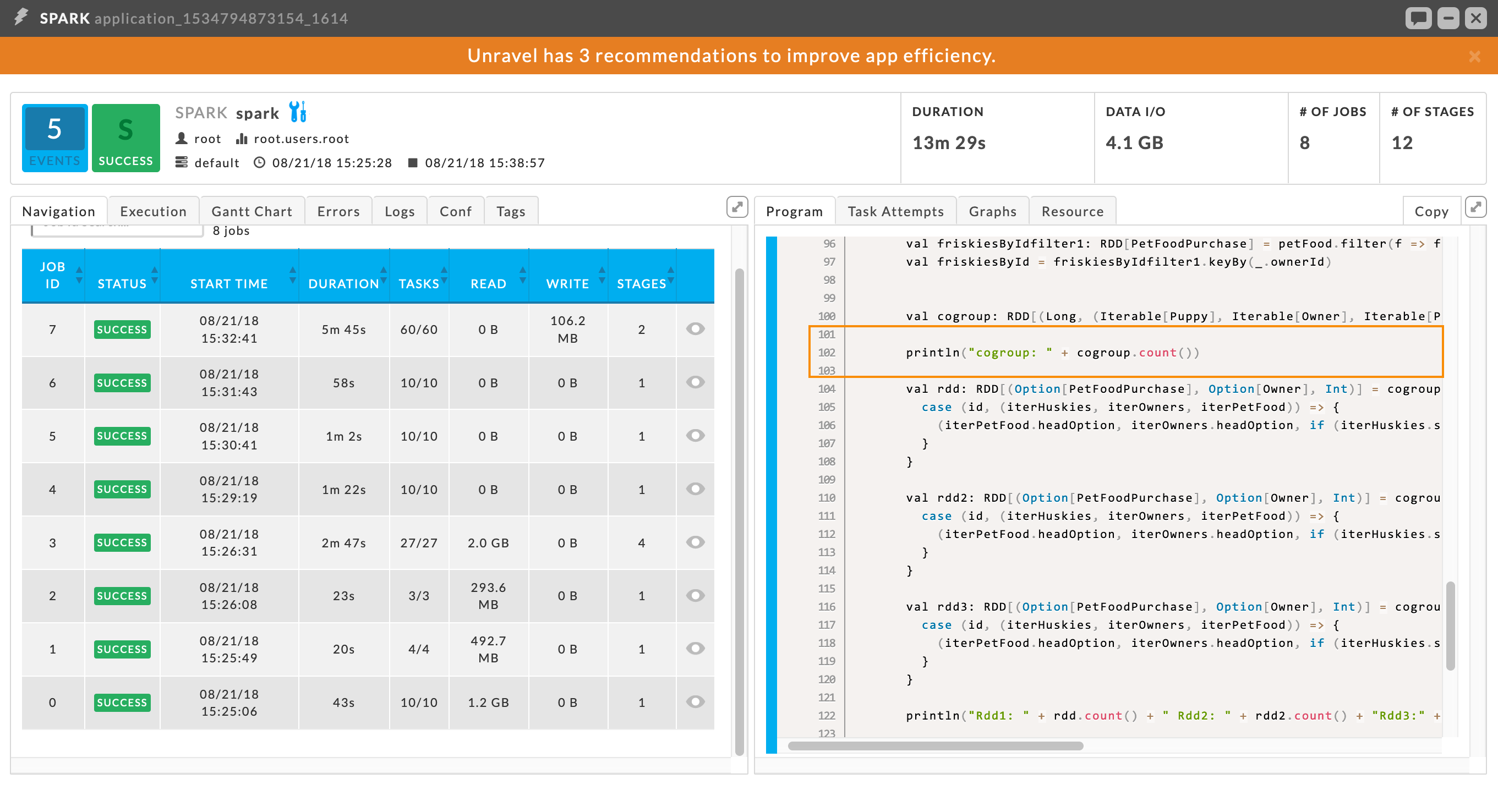
Unravel Insights makes it easy for you to understand where and when to use cache() in order to improve your app's performance. This is just one of the events (insights) that Unravel’s ML-driven approach generates to help you tune your Spark apps.
See our other use cases for further examples of how Unravel can save you a challenging and time consuming analysis with its it insights and recommendations to improve your app's performance.