Populating the Unravel Data Insights page
Reports > Data Insights is populated by Unravel analyzing your Hive Metastore tables along with your Hive query information. You must configure Unravel's connection to the Hive Metastore. Unravel Server collects information through the Hive API, which is similar to the beeline CLI and uses the JDBC database connection protocol.
1. Obtaining Hive Metastore details
This topic explains how to find the connection URL, driver name, username, and password for Hive or HiveServer2. You need these four settings to connect Unravel Server to the Hive Metastore.
From CDH version 5.5+, send the Cloudera Manager REST API request
http://.cloudera-manager-hostname-or-ip:7180/api/v12/cm/deploymentSearch the JSON response body for
metastore.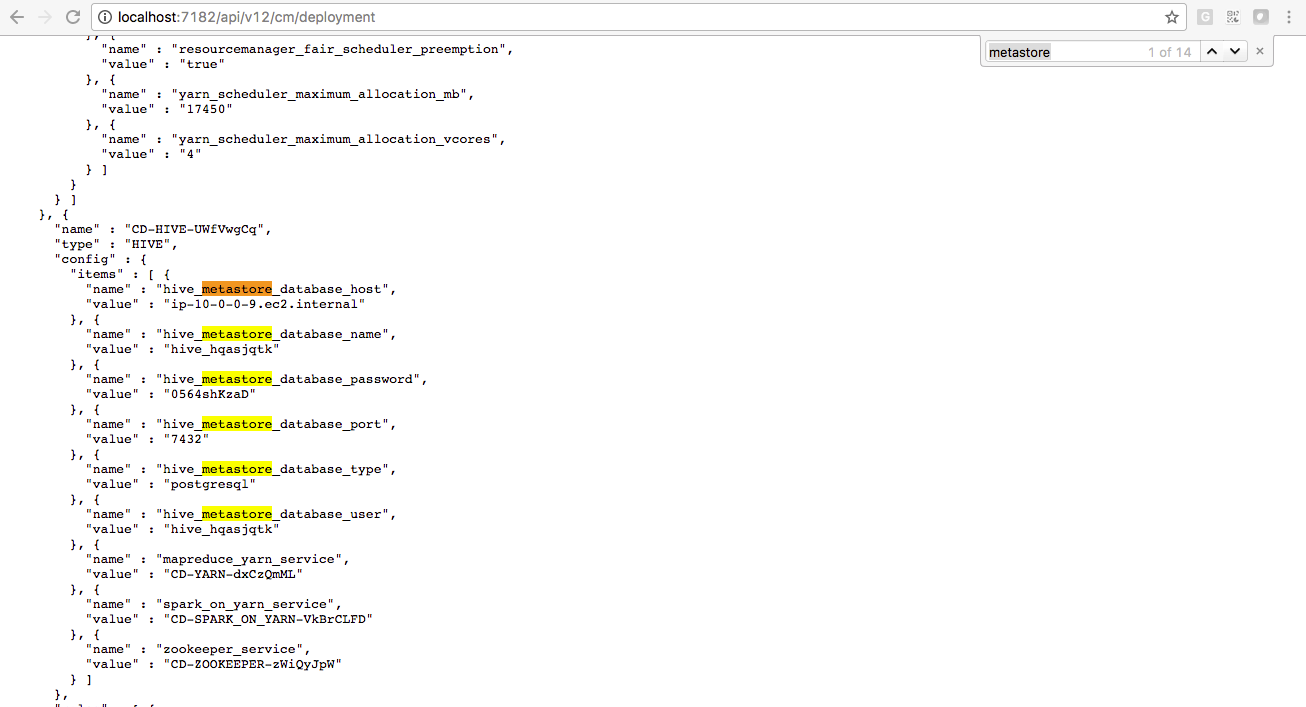
Copy the connection URL, driver name, username, and password.
You can get 3 of the 4 properties from Ambari, or get all 4 from the Azure portal:
Log in to the Azure portal.
Click HDInsight clusters, and select your cluster.
In the cluster's Overview window, click the link in the URL field.
This gets you to the Ambari UI.
In Ambari, click Hive | Configs | Advanced.
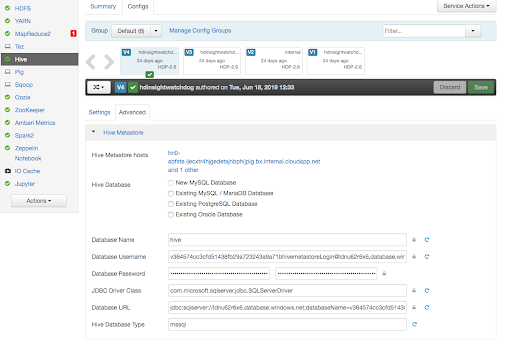
Get the four required settings:
For connection URL, use the value in the Database URL field.
In the screenshot, this is
jdbc:sqlserver://ldnu62r6x6.database.windows.net;databaseName=v364574cc3cfd51438fb29a723243a9a71bhivemetastore;trustServerCertificate=false;encrypt=true;hostNameInCertificate=*.database.windows.net;For the driver name, use the value in the JDBC Driver Class field.
In the screenshot, this is
com.microsoft.sqlserver.jdbc.SQLServerDriverFor username, use the value in Database Username field.
In the screenshot, this is
v364574cc3cfd51438fb29a723243a9a71bhivemetastoreLogin@ldnu62r6x6.database.windows.netThe password is encrypted; Ambari doesn't show it. Obtain the password from Azure instead.
From the Azure portal, find out the IP address to use for an SSH session to your cluster.
Open an SSH session to that IP address.
In
/etc/hive/conf/hive-site.xml, search for these values, and copy them to use as-is:javax.jdo.option.ConnectionURL javax.jdo.option.ConnectionDriverName javax.jdo.option.ConnectionUserName To get the Hive password, run this command at the Linux prompt:
sudo java -cp '/var/lib/ambari-agent/cred/lib/*' org.apache.ambari.server.credentialapi.CredentialUtil get javax.jdo.option.ConnectionPassword -provider 'jceks://file/var/lib/ambari-agent/cred/conf/hive_metastore/hive-site.jceks' 2>/dev/null
Open an SSH session to the cluster, open the Hive configuration file, /etc/hive/conf/hive-site.xml, and search for the four settings. For example, on EMR version 4.7.2, you'd see something like this:
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://ip-xx-xx-xx-xx:3306/hive?createDatabaseIfNotExist=true</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>xxxxxxxxxxx</value> <description>password to use against metastore database</description> </property>
To get the four required settings, contact your cluster's administrator.
2. Configure Unravel to access Hive Metastore
In order for the tab to populate correctly, you must configure the Hive Metastore Access parameters. You also have the option to configure the JDBC parameters managing JDBC pooling.
Download the right JDBC connector JAR for your database:
If you're using MySQL as the Hive Metastore database, download the MySQL JDBC connector JAR from MySQL Download ConnectorJ.
If you're using Oracle as the Hive Metastore database, download the Oracle JDBC connector JARs
ojdbc7.jarandojdbc6.jarfrom Oracle Database 12c Release 1 JDBC Driver Downloads.Note
Make sure the
unravelaccount has read permission.
Get details about the location of the Hive Metastore.
In CDH, use the following Cloudera Manager API to get the Hive metastore database name and port. By default, in CDH and HDP, the hive metastore database name is
hive.For TLS-secured Cloudera Manager
curl -k -u admin:admin "https://
cloudera-manager-host:7183/api/v11/clusters/cluster-name/services/hive/config"For non-TLS secured Cloudera Manager
curl -k -u admin:admin "http://
cloudera-manager-host:7183/api/v11/clusters/cluster-name/services/hive/config"or
curl -k -u admin:admin "http://
cloudera-manager-host:7180/api/v12/cm/deployment"
Look for
hive_metastore_database_host,hive_metastore_database_port,hive_metastore_database_userandhive_metastore_database_passwordin the JSON response body.For HDP or MapR, contact your cluster administrator.
Connect to the Hive metastore using the normal conversational interface for your underlying database (MySQL, PSQL Oracle, and so on) as an administrator or root user that can create new users and grant privileges.
For PostgreSQL, run the psql command as admin user
cloudera-scmon Cloudera embedded PostgreSQL server within the Cloudera Manager node.psql -U cloudera-scm -p 7432 -h localhost -d postgres
Create a new database user, such as
unravelka, grant the user READ access to the database, grant that user SELECT privileges on all tables in the Hive database, and give that user access from the Unravel server host.For MySQL, run the following command to create a new user
unravelkaand grant it SELECT privilege on the Hive metastore database:GRANT SELECT ON hive.* to 'unravelk'@'%' identified by 'unravelk_password'; flush privileges;
For PostgreSQL, run the following commands:
CREATE USER unravelk WITH ENCRYPTED PASSWORD 'unravelk_password'; GRANT CONNECT ON DATABASE hive TO unravelk; GRANT USAGE ON SCHEMA public TO unravelk; GRANT SELECT ON ALL TABLES IN SCHEMA public TO unravelk; GRANT SELECT ON ALL SEQUENCES IN SCHEMA public TO unravelk; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO unravelk; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT USAGE ON SEQUENCES TO unravelk;
Note
The default PostgreSQL admin password created by Cloudera Manager is stored in
/var/lib/cloudera-scm-server-db/data/generated_password.txt.For Oracle
Due to restrictions for accessing an Oracle database you need to create synonyms and select access for the Unravel user. See Configuring Oracle.
As the new user, use the conversational interface (MySQL, psql, Oracle, and so on) from Unravel Server to verify that the new user has access.
Update
/usr/local/unravel/etc/unravel.propertiesto use simple JDBC calls to get read-only details from Hive Metastore.com.unraveldata.metastore.use.jdbc=true
Download Microsoft JDBC Driver 7.0 for SQL Server JAR from Microsoft here to Unravel node.
Extract the downloaded file.
tar -xvzf sqljdbc_
version_enu.tar.gzCreate the following directories if they do not exist.
mkdir -p /usr/local/unravel/share/java
Copy mssql-jdbc-7.0.0.jre8.jar to the following locations.
sudo cp sqljdbc_7.0/enu/mssql-jdbc-7.0.0.jre8.jar /usr/local/unravel/share/java
3. Add the following properties
In /usr/local/unravel/etc/unravel.properties, update Hive metastore access information with the read-only username and the values you retrieved in step 1.
For example,
javax.jdo.option.ConnectionURL=jdbc:mysql://congo.unraveldata.com/hive javax.jdo.option.ConnectionDriverName=com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName=unravelka javax.jdo.option.ConnectionPassword=hadoop
If you are using Microsoft JDBC Driver 7.0 for SQL Server set the properties as follows.
javax.jdo.option.ConnectionURL=jdbc:sqlserver://jdbc_urljavax.jdo.option.ConnectionDriverName=com.microsoft.sqlserver.jdbc.SQLServerDriver javax.jdo.option.ConnectionUserName=usernamejavax.jdo.option.ConnectionPassword=password
4. Restart Unravel
sudo /etc/init.d/unravel_all.sh restart
5. Confirm Hive queries are displayed in the Unravel UI
Go to Unravel UI's Applications > Applications page to confirm that Hive queries are displayed. Approximately twenty-four hours after configuration the Reports > Data Insights > Details page displays a list of your Hive Metastore tables along with their KPIs and other details.