Multi-cluster configurations
The Multi-cluster feature allows you to manage multiple independent clusters from a single Unravel installation. You can dynamically add or remove the clusters.
Unravel can manage one default cluster and along with it either multiple on-prem clusters or multiple cloud clusters. Unravel does not support multi-cluster management of combined on-prem and cloud clusters.
Note
Unravel multi-cluster support is available only for fresh installs.
Multi-cluster deployment consists of installing Unravel on the Core node and Edge node. The following image depicts the basic layout of multi-cluster deployment.
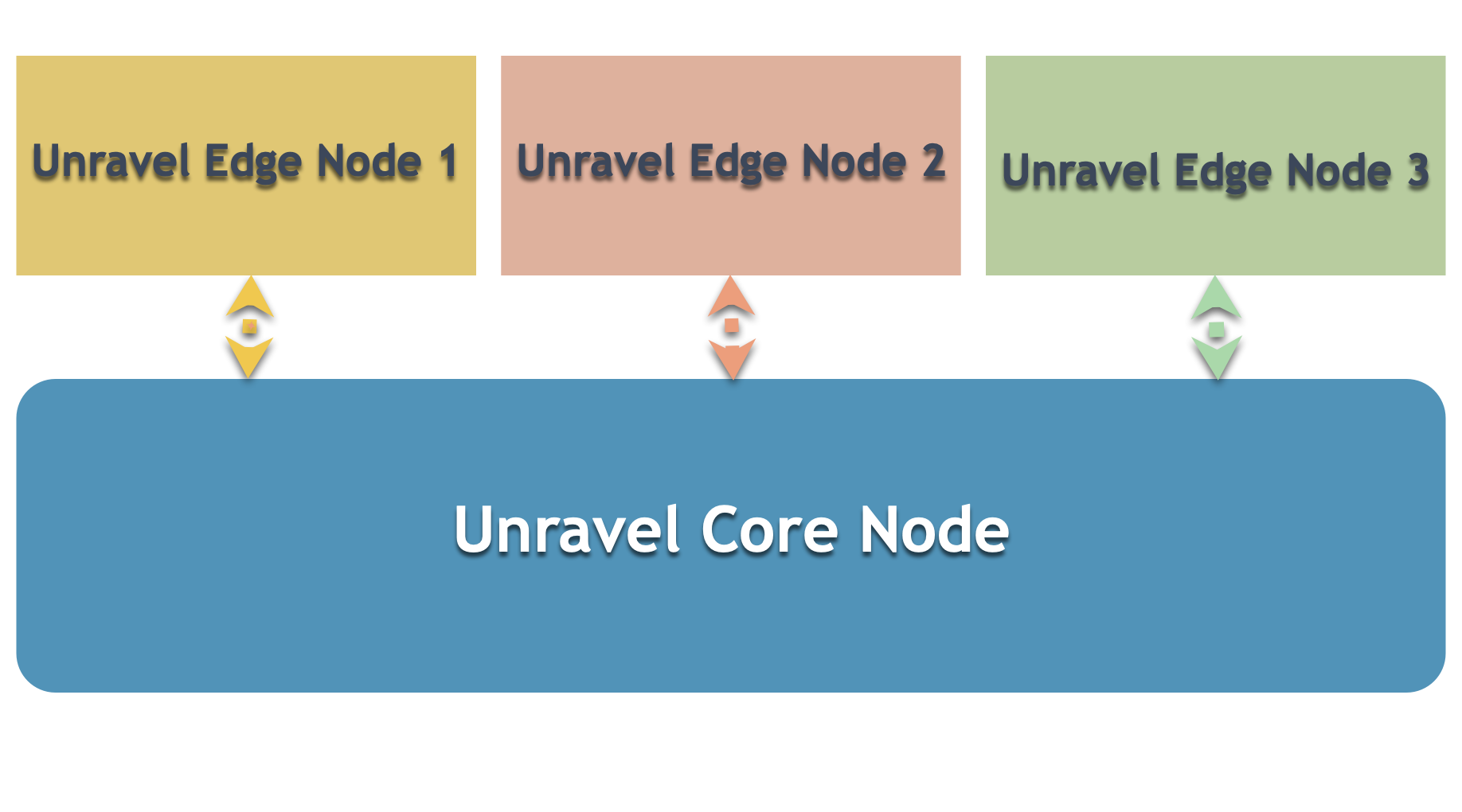
Configuring components accessed from the Core node
The following components are accessed from the Core node, where Unravel is installed.
Cloudera Manager (CM)
Ambari
Hive Metastore
Kafka
Pipeline (Workflows)
The following properties must be configured on the Core node in a multi-cluster setup.
Cloudera Manager - Multi-cluster
Ambari
Hive Metastore
Kafka
Pipelines
Configuring components accessed from the Edge node
In a multi-cluster deployment for on-prem platforms, the following properties must be added to the Edge node server, for MR jobs to load jhist and logs, HDFS path for jhist/conf, and yarn logs:
Property/Description | Default |
|---|---|
com.unraveldata.min.job.duration.for.attempt.log Minimum duration of a successful application or which executor logs are processed (in milliseconds). | 600000 (10 mins) |
com.unraveldata.job.collector.log.aggregation.base HDFS path to the aggregated container logs (logs to process). Do not include the hdfs://prefix. The log format defaults to TFile. You can specify multiple logs and log formats (TFile or IndexedFormat.) Example: com.unraveldata.job.collector.log.aggregation.base=TFile:/tmp/logs/*/logs/,IndexedFormat:/tmp/logs/*/logs-ifile/ | /tmp/logs/*/logs/ |
com.unraveldata.job.collector.done.log.base HDFS path to done directory of MR logs as per cluster configuration. Don't include the hdfs:// prefix For example: com.unraveldata.job.collector.done.log.base=/mr-history/done | /user/history/done |
com.unraveldata.spark.eventlog.location All the possible locations of the event log files. Multiple locations are supported as a comma-separated list of values. This property is used only when the Unravel sensor is not enabled. When the sensor is enabled, the event log path is taken from the application configuration at runtime. | hdfs:///user/spark/applicationHistory/ |
The following properties must be added for Tez to the Edge node server in a multi-cluster deployment for on-prem platforms.