- Home
- Documentation
- Troubleshooting
- Unravel installation and upgrade issues
Unravel installation and upgrade issues
This section provides information for troubleshooting and recovery.
Refer to PostgreSQL upgrade fails.PostgreSQL fails while upgrading
Sometimes, the edge node fails to communicate with the core node and java.net.ConnectException: Connection refused error is displayed. When you check the daemon log, you will notice that the issue is caused when the user limit is reached for inotify watches: Caused by: java.io.IOException: User limit of inotify watches reached
Solution
To resolve this issue, you can check and increase the threshold limit of the inotify watches on the core node as follows:
Ensure that the maximum number of inotify watches has been reached on the core node.
After ensuring that the inotify watches have reached the upper limit, access the
/etc/sysctl.conffile as a root user.Using an editor, update
/etc/sysctl.conffile and set the kernel parameterfs.inotify.max_user_watchesto an increased limit. For example:fs.inotify.max_user_watches=524288.Apply the changes.
sysctl -p
When you are upgrading from Unravel version 4.6.2x multi-cluster environment and activate the v4.7x version, the Precheck fails with the following Hadoop error:
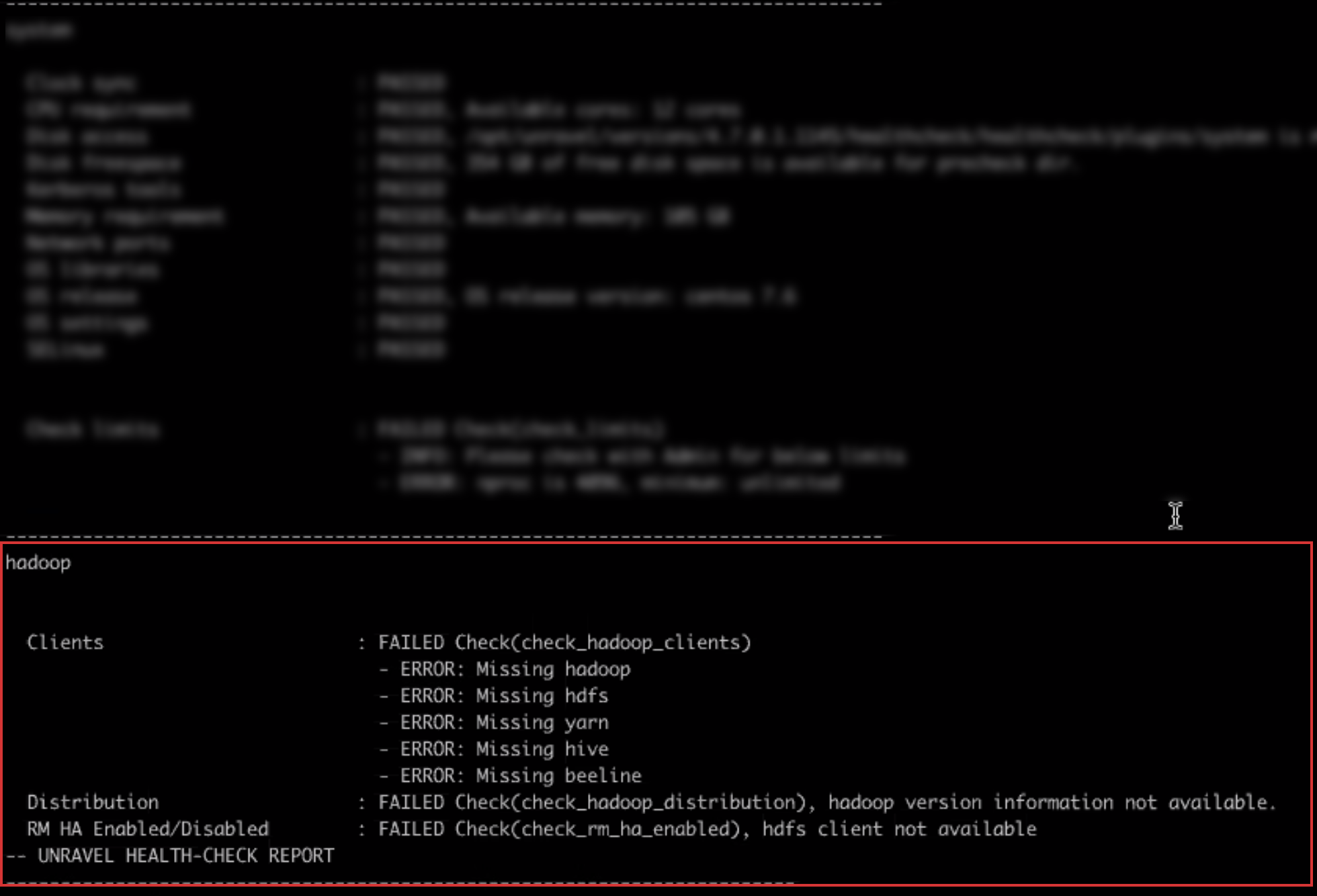
Solution
This is because of the com.unraveldata.multicluster.default_cluster.enabled property, which indicates whether the core node is directly monitoring the Hadoop cluster. By default, this property is set to true in Unravel 4.6.2x.
However, if you are not using the core node for Hadoop monitoring, you must manually set this property to false before performing the upgrade in a multi-cluster environment. This will eliminate the Hadoop error in Precheck when you are upgrading in a multi-cluster environment from Unravel version 4.6.2x to 4.7x.
Before you upgrade to v4.7x, do the following:
Stop Unravel
<Unravel installation directory>/unravel/manager stop
Set the com.unraveldata.multicluster.default_cluster.enabled property to false.
<Unravel installation directory>/unravel/manager config properties set com.unraveldata.multicluster.default_cluster.enabled false
Apply the changes.
<Unravel installation directory>/unravel/manager refresh files
Start Unravel.
<Unravel installation directory>/unravel/manager start
If you supply a configuration for an instance Group in a running cluster on EMR, it overrides the Unravel Sensor properties added by the bootstrap script.
Solution
You must add unravel properties along with the new configurations that are modified.
Whenever you face any issues during installation, you should first check the following log files to diagnose the issues:
The following log files are located in the <Unravel installation directory>/logs directory.
Log files | Description |
|---|---|
| All the commands that run through manager tool generate logs into this file. To diagnose thoroughly, run the manager commands with --debug. The setup process is run due to some commands. These get logged in the |
| When you are doing a first-time install, before the directory structure is created, this log file exists as 2020-06-09 21:23:12 Sending logs to: /tmp/unravel-setup.log 2020-06-09 21:23:12 Prepare to install with: /home/unravel/edge.yaml 2020-06-09 21:23:14 Sending logs to: <Unravel installation directory>/logs/setup.log |
| This log file is used to track the status of the services and restart in case the services get stopped due to any issues. Normally logs generated by the stop/start script go to their respective |
| Each of the unravel service has a stop/start script that logs to a 2020-06-11 18:28:54 INFO *** Starting pgsql... waiting for server to start....2020-06-11 11:28:54.773 PDT [36976] LOG: listening on IPv4 address "0.0.0.0", port 4339 2020-06-11 11:28:54.773 PDT [36976] LOG: listening on IPv6 address "::", port 4339 2020-06-11 11:28:54.773 PDT [36976] LOG: listening on Unix socket "<Unravel installation directory>/run/.s.PGSQL.4339" 2020-06-11 11:28:54.860 PDT [36976] LOG: redirecting log output to logging collector process 2020-06-11 11:28:54.860 PDT [36976] HINT: Future log output will appear in directory "<Unravel installation directory>/logs". done server started 2020-06-11 18:28:54 INFO *** Starting pgsql... Started 2020-06-11 18:30:07 INFO *** Stopping pgsql... waiting for server to shut down.... done server stopped 2020-06-11 18:30:08 INFO *** Stopping pgsql... Stopped |
Whenever the installation process gets broken, do the following:
Stop Unravel.
manager stop
If the manager does not work, open the
servicesdirectory, each service has a stop.sh script. Stop the service monitor (monit). and then run the stop.sh script.In case you do not have stop.sh scripts, send SIGTERM to all the services starting with the service monitor (monit)
Caution
Avoid using SIGKILL since that may cause some file corruption.
Reinstall Unravel using the content in the
datadirectory.
Solution
Stop Unravel.
Assuming that you have installed Unravel in
/opt, run the following command:/opt/unravel/manager refresh files
This regenerates all the scripts and configuration files.
In case the refresh command did not regenerate the files or the manager is broken, then check
<Unravel installation directory>/data/conf/current.yamland run the following. The current.yaml file shows the current version that is installed.<Unravel installation directory>/versions/X.Y.Z/setup --config=<Unravel installation directory>/data/conf/unravel.yaml
Start Unravel.
<Unravel installation directory>/unravel/manager start
Solution
Stop Unravel.
Check
<Unravel installation directory>/data/conf/current.yamlfor the current version that is installed.Unpack that same version in the exact location where it was deployed earlier.
tar zxf unravel-SAME-VERSION.tar.gz -C /opt
Run the following:
<Unravel installation directory>/versions/X.Y.Z/setup --config=<Unravel installation directory>/unravel/data/conf/unravel.yaml
Start the manager.
<Unravel installation directory>/unravel/manager start
Solution
Stop Unravel.
Restore the backup of the data directory.
Open
data/conf/unravel.effective.yamland check for the following key paths:base:
<Unravel installation directory>data:
<Unravel installation directory>/data
Make sure that the
datais restored to the right location.Make sure the unravel user has full access and ownership of the
baselocation and everything in it.Check< Unravel installation directory>
/data/conf/current.yamlfor the current version that is installed.Unpack that same version in the exact location where it was deployed earlier.
tar zxf unravel-SAME-VERSION.tar.gz -C /opt
Run the following:
<Unravel installation directory>/versions/X.Y.Z/setup --config=<Unravel installation directory>/data/conf/unravel.yaml
Start Unravel.
<Unravel installation directory>/manager start
HCatalog is part of Apache Hive. In such a case, the Hive Hook configuration is found, but the libraries that execute Hive Hook are missing.
Since this is a shell action, libraries need to exist on every node locally so that Sqoop command can locate it during command execution. You can add Unravel Hive Hook jar in /var/lib/sqoop or wherever the hive-hcatalog jars are located in the cluster.
When Unravel is stopped and restarted immediately, the following error is displayed:
[Errno 1] Operation not permitted [Errno 1] Operation not permitted INS00160: Process '3366' is not owned by unravel INS00161: Process '3366' is not owned by unravel, this can come from a stale pid file '/opt/unravel/run/mysql.pid'
Solution
When you do an ungraceful shutdown, the PID files will remain, and if the PID is reused, it may cause problems. You should ensure that unravel is stopped (it will if the server was just restarted) and delete the PID files in /opt/unravel/run
The upgrade of Unravel fails.
Solution
You can roll back the upgrade of Unravel to the release from which you upgraded.
Caution
Ensure that you have taken a backup of the data directory and the external database (if using). For instructions, see Upgrading Unravel.
To revert to the original upgrade, perform the following steps:
Stop Unravel.
<Unravel installation directory>/unravel/manager stopRestore the
datadirectory from the archive.If using an external database, restore the database from the backup.
Note
For the details on how to restore the database, refer to the documentation for your corresponding database.
Run the following command to reconfigure Unravel using the restored data:
/opt/unravel/versions/
<ORIGINAL VERSION>/setup --config /opt/unravel/data/conf/unravel.yaml
Symptom | Problem | Remedy |
|---|---|---|
|
| Install Unravel RPM on Unravel host. or Verify that user |
| Unravel hive hook JAR was not found in in | Confirm that the or Put the Unravel hive-hook JAR corresponding to cd /usr/local/unravel/hive-hook/; cp unravel-hive- |