Overview
Unravel provides full stack coverage and a unified, end-to-end view of everything going on in your environment. Unravel helps you to understand and optimize performance across every application and business unit both in the cloud and on-premises. It provides visibility across the entire data stack, collecting data from every pipeline, every job, wherever those workloads are running.
Unravel creates a correlated data model that provides the full context you need on your apps and resources to properly plan, manage, and improve performance.

Unravel enables you to:
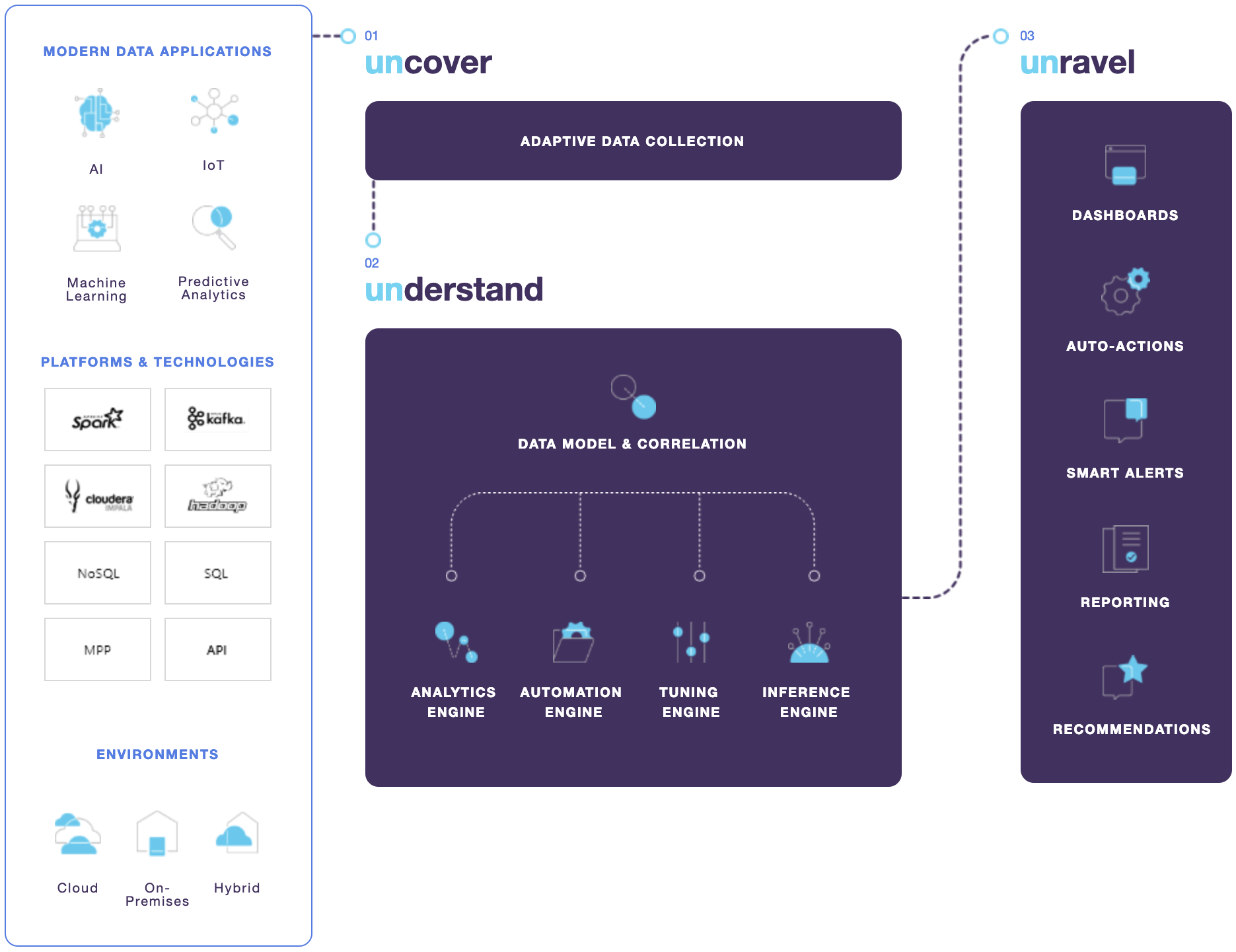
Uncover: See how your data pipelines are performing from end to end. Get a unified view of your entire stack. Unravel collects performance data from every platform, system, and application then uses agentless technologies and machine learning to model your data pipelines from end to end.
Understand: Correlate and analyze all your applications, users, and resource data. Explore, correlate, and analyze everything in your big data environment. Unravel's data model reveals dependencies, issues, and opportunities, how data and resources are being used, what's working, and what's not.
Unravel: Troubleshoot, tune, and optimize your ecosystem with AI-powered insights and recommendations. Don't just monitor performance – quickly troubleshoot and rapidly remediate issues. Leverage AI-powered recommendations to automate performance improvements, lower costs, and prepare for what's next
Unravel goes beyond raw visibility to provide concrete, providing AI-driven advice such as:
Code you can use.
Specific settings you can tweak.
Recommendations you can immediately implement or automate to fix issues and optimize performance.
The Unravel Data Operations Platform helps operations engineers, application developers, and enterprise architects reduce the complexity of delivering reliable application performance – providing unified visibility and operational intelligence to optimize your entire ecosystem.
In summary, problems solved by Unravel:
APM for Big Data
AI for DataOps
Cloud Migration
Resource and Cost Optimization
Troubleshooting and Root Cause Analysis
Features
Unravel provides a unified "single pane of glass" for the monitoring and management of your cluster whether on-premises, running in the cloud or a hybrid of both.
Dashboards: Provides an overall picture of your cluster's resources, usage, and activities.
Application Performance Manager (APM): Organizes and displays your application's information allowing you to analyze and locate problems from a single interface and allows you to compare data between various runs.
Auto-Actions & Alerts: Defines automatic actions, from notification to killing an app, to be taken based upon your criteria.
Reporting: Provides a wide variety of reports analyzing everything from your file structure to cluster optimization to migrating to the cloud.
Insights and Recommendations: Unravel AI's engine helps you fine-tune your cluster, applications, and tables to help you optimize for reliability and performance.
Support Role-Based Access Control: Provides the ability to control the access/visibility users have within the Unravel UI based on their role.
See here for a video giving an overview of Unravel.
Where Does Unravel Reside
On-premises Architecture
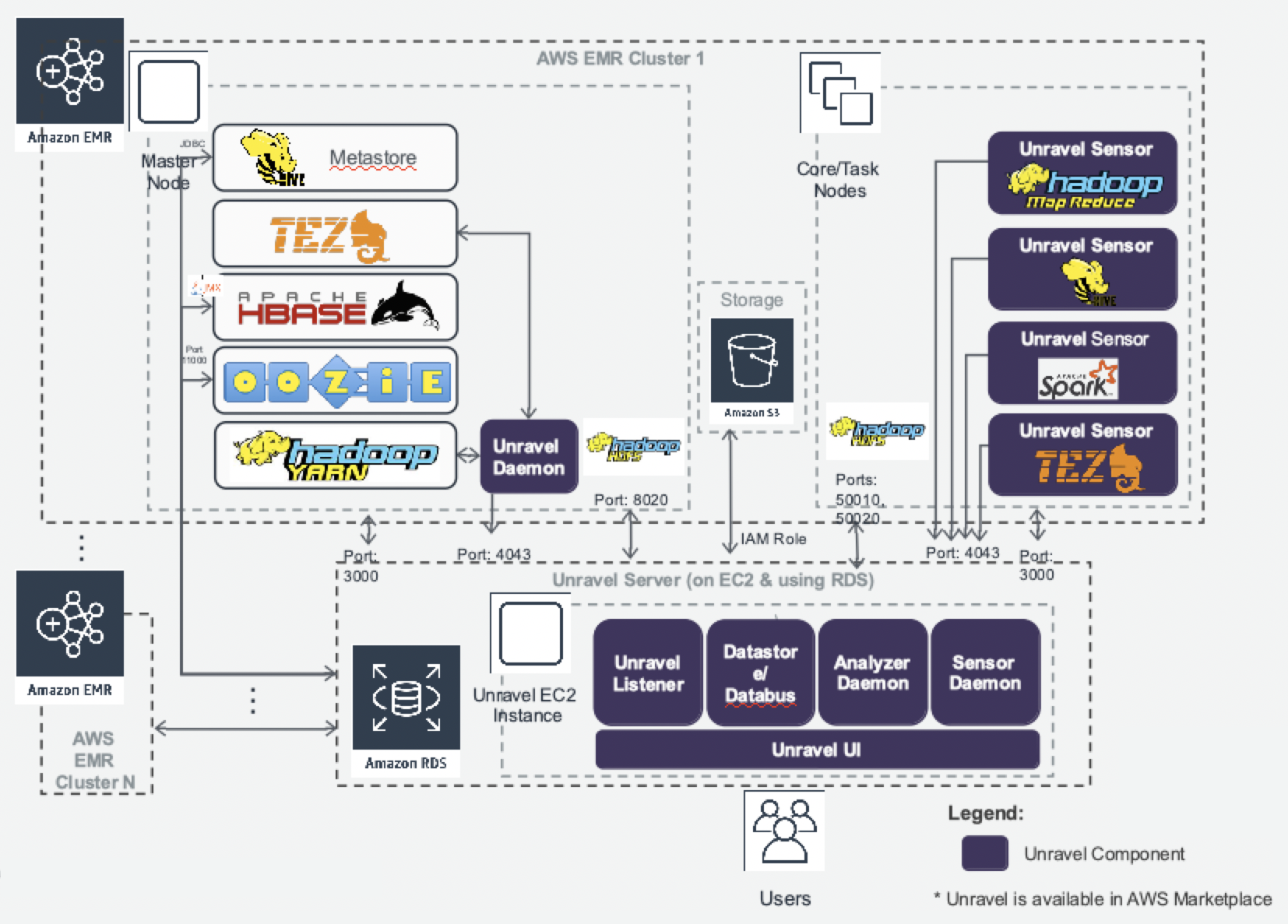
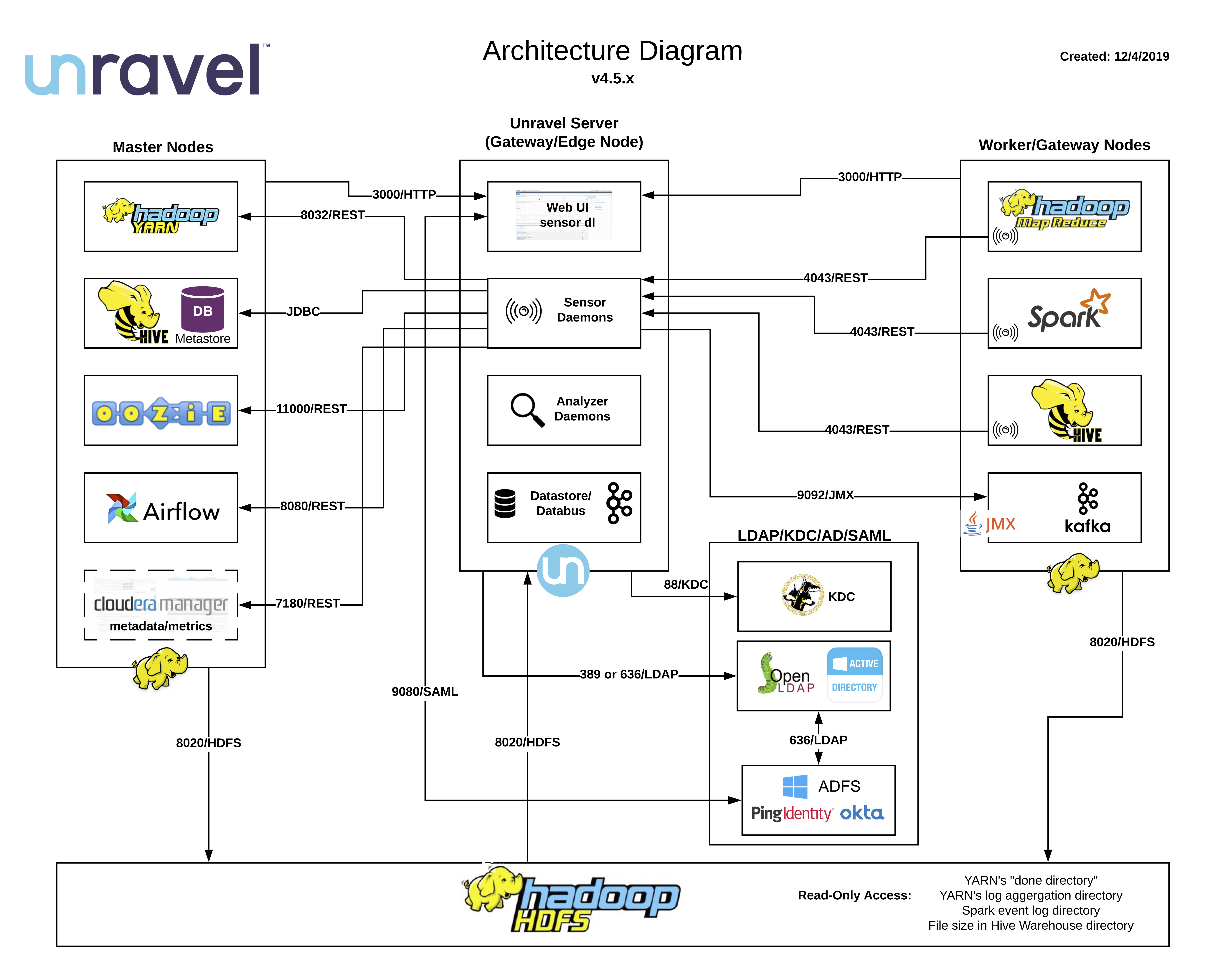
Unravel Server is positioned in a Hadoop cluster on its own Gateway/Edge node to communicate with HDFS and TaskTracker nodes, and to enable client access to Unravel Web UI. A basic deployment takes two hours or less. You can deploy Unravel to preserve business continuity after a disruptive event.
Once deployed, Unravel Server begins to collect information from relevant services like YARN, Hive, Oozie, Spark, Pig, and MapReduce jobs via HDFS. Unravel analyzes this information and store its analyses in its database. Unravel Web UI displays information from the database, as well as real-time event streams it receives directly from Unravel Server.
After deployment, advanced setup steps are optional, but may include:
Deploying Unravel Sensors for Hive and Spark, which can push additional metadata to Unravel Server.
In YARN, enabling log aggregation.
In Oozie, pushing information via the Oozie REST API.
Installing OnDemand for report generation.
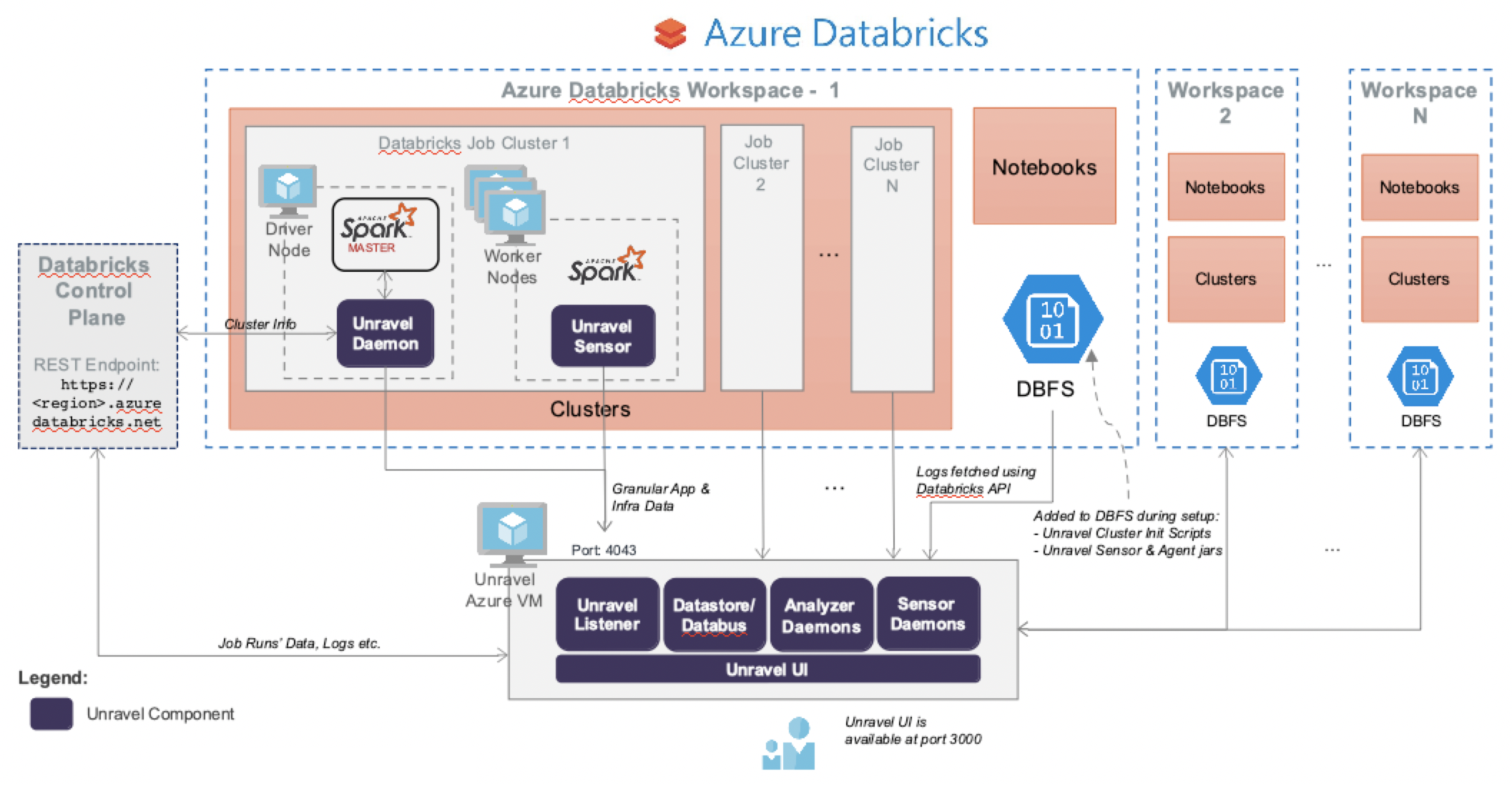
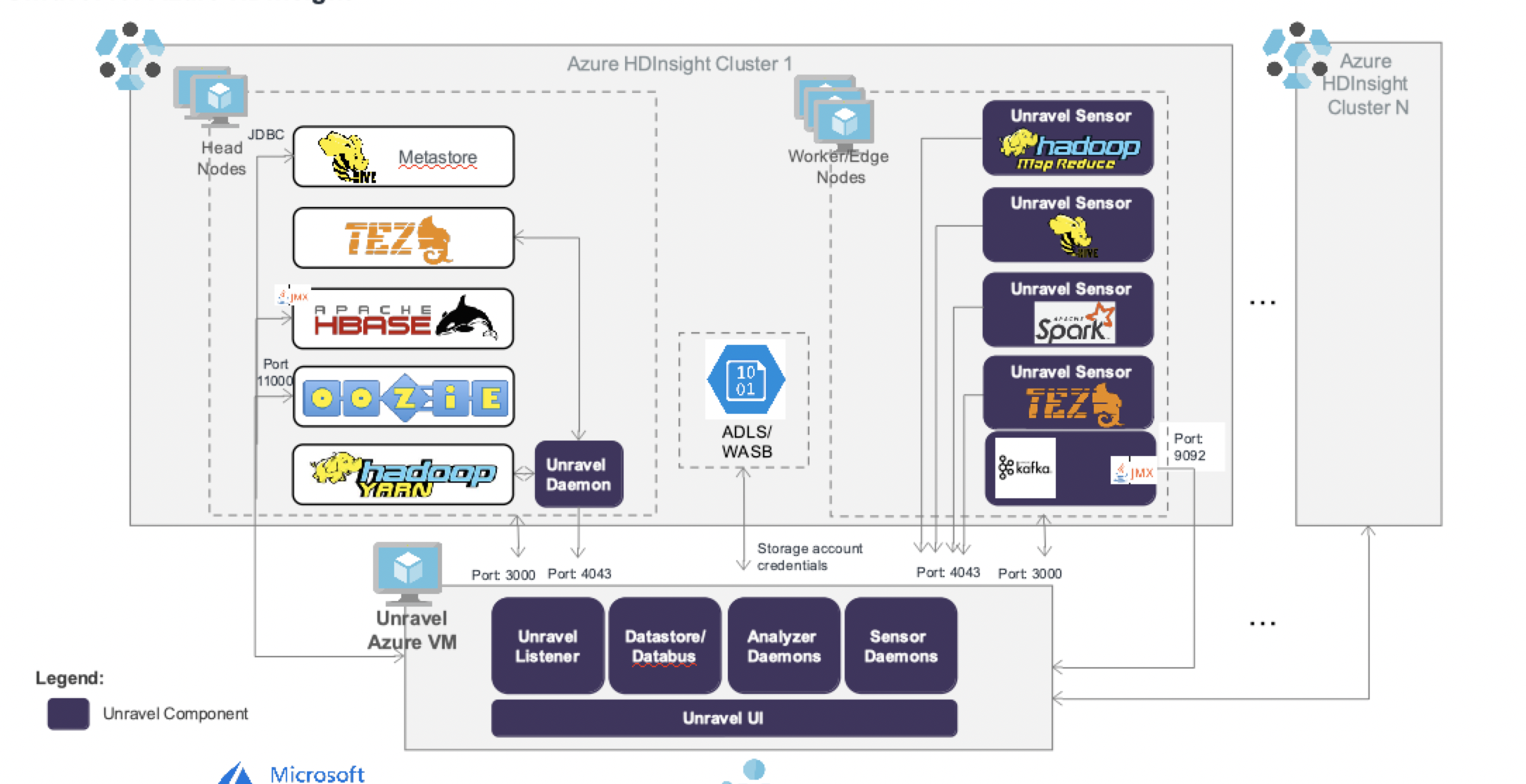
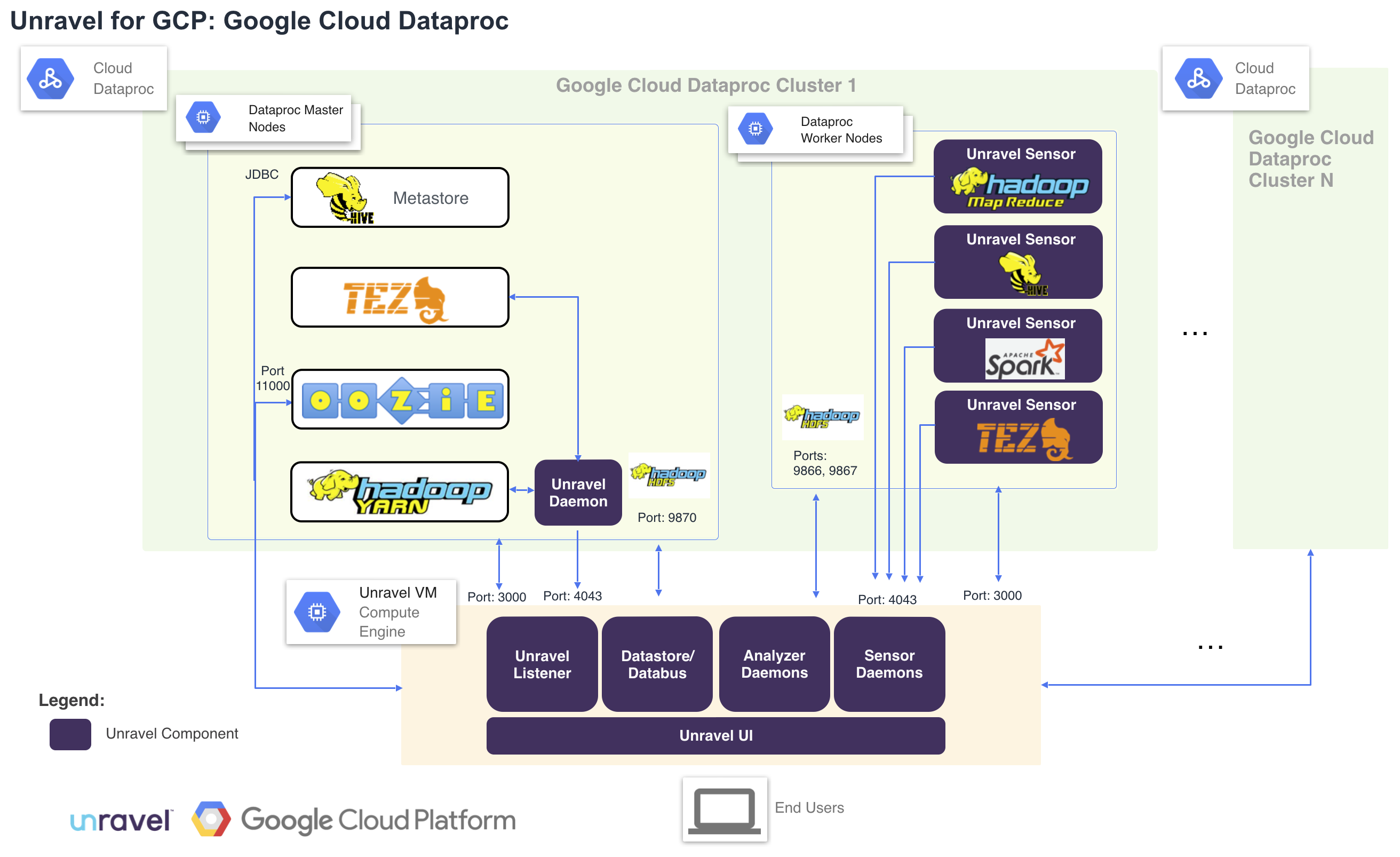
Cloud Architecture
In order to manage, monitor, and optimize the modern data applications running on your clusters, Unravel server needs data corresponding to the cluster as well as about the data apps running on them. This information includes metrics, configuration information, and logs. Some of this data is pushed to Unravel, while some are pulled by the daemons in Unravel Server.