Configure metadata processing for Delta tables
Do the following to configure metadata processing for the Delta tables:
1. Schedule a job to extract metadata
You must schedule a job on your workspace to run the Delta table extractor to extract the metadata into a JSON file. Do the following to run the job:
Get the
metadata_extractor_dbr_10_1.jarfile from Unravel Customer Support and upload the jar file to your respective Databricks dbfs location.On your workspace, click Create > Job.
In the Task tab, specify the following:
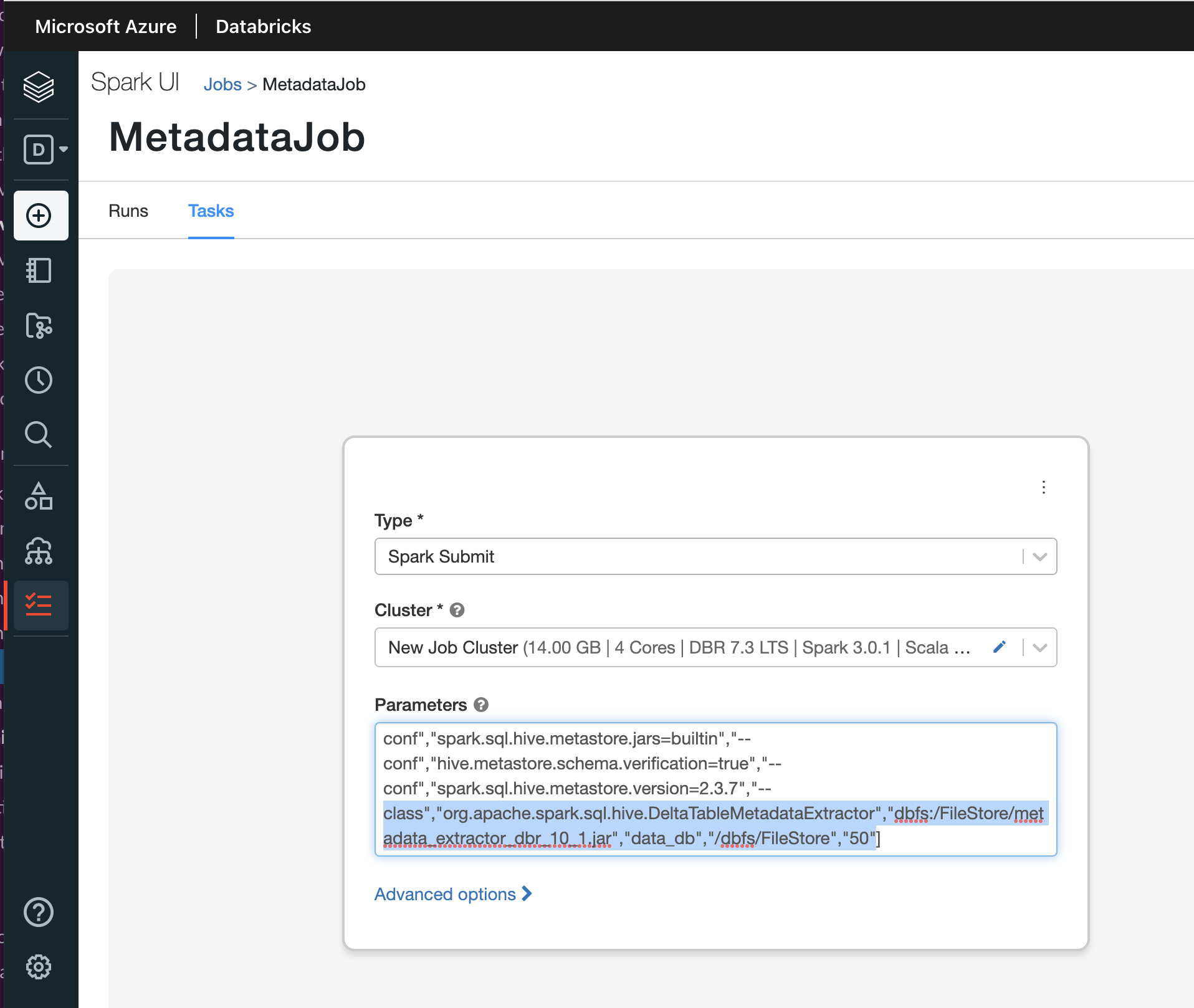
From the Type drop-down, select Spark Submit.
From the Cluster drop-down, select a cluster. The cluster should be of the latest (Databricks, Spark, Scala) version.
In the Parameters text box, specify the following parameters as mentioned in the example:
["--class","org.apache.spark.sql.hive.DeltaTableMetadataExtractor","dbfs:/FileStore/metadata_extractor_dbr_10_1.jar","customer_db","/dbfs/FileStore/delta/","500"]
Parameters
Description
"dbfs:/FileStore/metadata_extractor_dbr_10_1.jar"
Specify the location of the jar file that you had uploaded to dbfs in Step 1.
"customer_db"
The first argument, specify a valid database name. (Mandatory)
"/dbfs/FileStore/delta"
The second argument, which is the output directory location where the metadata files will be stored. (Optional)
"500"
The third argument, which is the number of Delta tables. This can go up to 1000. (Optional)
A metadata file is generated in DBFS. You must copy this file to Unravel node.
2. Set up Unravel to process Delta table metadata
Copy the metadata file from DBFS to any location in Unravel node.
Run the following command from the Unravel installation directory.
<Unravel Installation directory>/unravel/manager run script delta_file_handoff.sh </path/to/metadata file>
Log onto Unravel UI, navigate to Data page > Tables and check in the Storage Format column for the Delta tables listing.