Using Azure HDInsight APIs
This section explains how to use the Azure CLI for common actions.
Tip
Best practice is to install the Azure CLI on a docker container.
Submit a script action
Log into the Azure CLI.
az login
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ######### to authenticate.
Run the script action.
Warning
First, refer to the script you want to run and ensure you have its proper parameters. You might need to remove any "
--" from the parameters.azure hdinsight script-action create $CLUSTER -g $RESOURCEGROUP -n $SCRIPTNAME -u $SHELLSCRIPT -p 'unravel-server $PRIVATEIP:3000 spark-version $MAJOR.$MINOR.$PATCH' -t "headnode;workernode;edgenode"
Where:
-gis the Resource Group name-nis the name of this script action task-uis the script path-pis a list of input parameters for the script-tis a semicolon-separated list of node types
For example,
azure hdinsight script-action create DEVCLUSTER -g UNRAVEL01 -n unravel-script-action -u https://raw.githubusercontent.com/unravel-data/public/master/hdi/hdinsight-unravel-spark-script-action/unravel_hdi_spark_bootstrap_3.0.sh -p 'unravel-server 128.164.0.1:3000 --spark-version 2.3.0' -t "headnode;workernode;edgenode"
Create an edge node
An edge node is a VM on an HDInsight cluster that only has the Hadoop client installed instead of any servers or daemons.
Determine which ARM template and parameter file to download to the workstation that contains Azure CLI:
Option A: An edge node that also runs the Unravel script (recommended)
Option B: An edge node that only runs a simple script,
emptynode-setup.sh
Download the ARM template and JSON parameter files into your configured Azure CLI workstation.
curl
filename-oname.jsonModify the VM type, parameters, Kafka/Spark version, and so on.
For example,
In the ARM template, edit these fields as appropriate.
"vmSize": "Standard_D3_v2" "parameters": "unravel-server $PRIVATEIP:3000 spark-version $MAJOR.$MINOR.$PATCH" "applicationName1": "$NEW_EDGE_NODE_HOSTNAME"
In the parameter file, modify the cluster name.
"clusterName": { "value": "$MY_CLUSTER_NAME" }
Validate template before deployment.
az group deployment validate --resource-group "$RESOURCEGROUP" --template- file azuredeploy.json --parameters azuredeploy.parameters.json { "error": null, ... "provisioningState": "Succeeded", ... }Create the edge node.
This should take 10-15 minutes to run since it has to provision a VM and install the Hadoop binaries.
az group deployment create --name deploymentname --resource-group "$RESOURCEGROUP" --template- file azuredeploy.json --parameters azuredeploy.parameters.json
Verify that the changes have been added to Ambari.
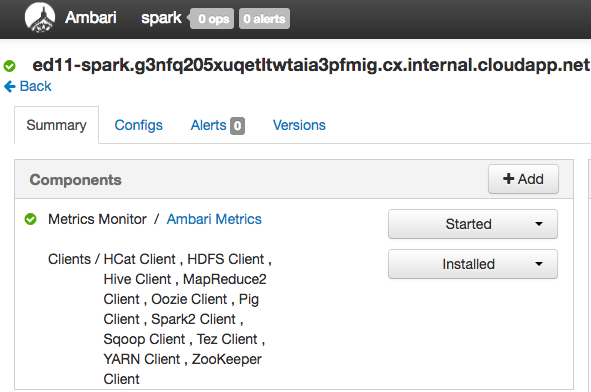
Auto-scale the cluster
HDInsight allows you to resize your cluster up/down to meet your current demands.
From the Azure portal, navigate to HDInsight Clusters |
your-cluster| Cluster Size.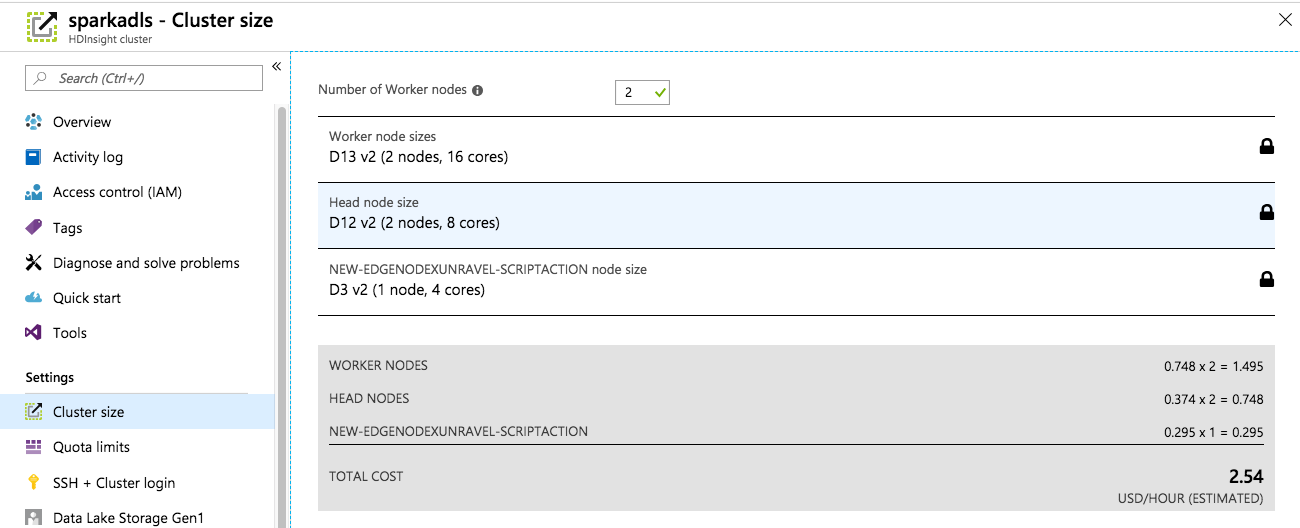
Enter your desired number of workers and validate that you have enough resources for your resource group and region (based on any quotas).
Click Save.
HDInsight takes the appropriate action:
For downsizing, HDInsight runs the Decommission command some number of workers on the DataNode, NodeManager, and HBase RegionServer processes (if it exists). Once drained, it removes the VM from Ambari and then from the cluster.
For upsizing, HDInsight provisions new VM, installs the Hadoop bits, and adds the worker components (DataNode, NodeManager, and potentially HBase RegionServer).

Note
If the Unravel script action was also "persisted" to run on "worker nodes", then new VMs will automatically run a custom command for the Unravel bootstrap script.
