[INTERNAL] Update the Azure Resource Manager if needed
For the dev team, you may need to update the ARM (Azure Resource Manager) Template for Kafka or Spark clusters:
[INTERNAL] Step 3: Create Unravel VM using the ARM template
Unravel VM can be deployed using Azure Resource Manager (ARM) template. This can automate the Unravel VM node setup; however the ARM template needs to be updated to reflect your specific environment.
The following ARM templates and parameter JSON file are for reference only. You need to update or create your own template files.
This example template creates an Azure "standard E8s V3" VM in the existing VNET and subnet, and it adds a data disk on the VM for the /srv mount point.
Note
You will need to update VNET, subnetRef, vmName, adminPassword before running the ARM template to create VM
Optionally change the size of data disk; it is currently set to 500G. If you change the disk size, update unravel-setup.sh script (search for 500).
For CentOS 7.3 Unravel VM
ARM template | |
|---|---|
Parameter file |
For RedHat 7.4 Unravel VM
ARM template | |
|---|---|
Parameter file |
Note
Both ARM template and parameter files have to be modified to fit your Azure environment
This ARM template embedded with Azure Extension script to download and install Unravel RPM. The Azure Extension script for Unravel RPM installation
Extension script for CentOS 7.3 | |
|---|---|
Extension script for CentOS 7.4 |
Note
The custom extension script will fix most of the basic unravel configuration; however you will have to manually edit /usr/local/unravel/etc/unravel.properties file for blob storage account or data lake store access information.
For instructions on editing unravel.properties, see Step 1.
Below is the content of this extension script
# Download unravel rpm
/usr/bin/wget http://preview.unraveldata.com/unravel/RPM/4.2.7/Azure/unravel-4.2.7-Azure-latest.rpm
BLOBSTORACCT=${1}
BLOBPRIACKEY=${2}
BLOBSECACKEY=${3}
DLKSTOREACCT=${4}
DLKCLIENTAID=${5}
DLKCLIENTKEY=${6}
DLKCLITOKEPT=${7}
DLKCLIROPATH=${8}
# Prepare the VM for unravel rpm install
/usr/bin/yum install -y ntp
/usr/bin/yum install -y libaio
/usr/bin/yum install -y lzop
/usr/bin/systemctl enable ntpd
/usr/bin/systemctl start ntpd
/usr/bin/systemctl disable firewalld
/usr/bin/systemctl stop firewalld
/usr/sbin/iptables -F
/usr/sbin/setenforce 0
/usr/bin/sed -i 's/enforcing/disabled/g' /etc/selinux/config /etc/selinux/config
sleep 30
# Prepare disk for unravel
mkdir -p /srv
DATADISK=`/usr/bin/lsblk |grep 500G | awk '{print $1}'`
echo $DATADISK > /tmp/datadisk
echo "/dev/${DATADISK}1" > /tmp/dataprap
echo "Partitioning Disk ${DATADISK}"
echo -e "o\nn\np\n1\n\n\nw" | fdisk /dev/${DATADISK}
DATAPRAP=`cat /tmp/dataprap`
DDISK=`cat /tmp/datadisk`
/usr/sbin/mkfs -t ext4 ${DATAPRAP}
DISKUUID=`/usr/sbin/blkid |grep ext4 |grep $DDISK | awk '{ print $2}' |sed -e 's/"//g'`
echo "${DISKUUID} /srv ext4 defaults 0 0" >> /etc/fstab
/usr/bin/mount -a
# install unravel rpm
/usr/bin/rpm -U unravel-4.2.7-Azure-latest.rpm
/usr/bin/sleep 5
# Update Unravel Lic Key into the unravel.properties file
# Obtain a valid unravel Lic Key file ; the following is just non working one
echo "com.unraveldata.lic=1p6ed4s492012j5rb242rq3x3w702z1l455g501z2z4o2o4lo675555u3h" >> /usr/local/unravel/etc/unravel.properties
echo "export CDH_CPATH="/usr/local/unravel/dlib/hdp2.6.x/*"" >> /usr/local/unravel/etc/unravel.ext.sh
# Update Azure blob storage account credential in unravel.properties file
# Update and uncomment the following lines to reflect your Azure blob storage account name and keys
if [ $BLOBSTORACCT != "NONE" ] && [ $BLOBPRIACKEY != "NONE" ] && [ $BLOBSECACKEY != "NONE" ]; then
echo "blob storage account name is ${BLOBSTORACCT}"
echo "blob primary access key is ${BLOBPRIACKEY}"
echo "blob secondary access key is ${BLOBSECACKEY}"
echo "# Adding Blob Storage Account information, Update and uncomment following lines" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.hdinsight.storage-account-name-1=fs.azure.account.key.${BLOBSTORACCT}.blob.core.windows.net" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.hdinsight.primary-access-key=${BLOBPRIACKEY}" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.hdinsight.storage-account-name-2=fs.azure.account.key.${BLOBSTORACCT}.blob.core.windows.net" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.hdinsight.secondary-access-key=${BLOBSECACKEY}" >> /usr/local/unravel/etc/unravel.properties
else
echo "One or more of your blob storage account parameter is invalid, please check your parameter file"
fi
sleep 3
if [ $DLKSTOREACCT != "NONE" ] && [ $DLKCLIENTAID != "NONE" ] && [ $DLKCLIENTKEY != "NONE" ] && [ $DLKCLITOKEPT != "NONE" ] && [ $DLKCLIROPATH != "NONE" ]; then
echo "Data Lake store name is ${DLKSTOREACCT}"
echo "Data Lake Client ID is ${DLKCLIENTAID}"
echo "Data Lake Client Key is ${DLKCLIENTKEY}"
echo "Data Lake Access Token is ${DLKCLITOKEPT}"
echo "Data Lake Client Root Path is ${DLKCLIROPATH}"
echo "# Adding Data Lake Account information, Update and uncomment following lines" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.adl.accountFQDN=${DLKSTOREACCT}.azuredatalakestore.net" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.adl.clientId=${DLKCLIENTAID}" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.adl.clientKey=${DLKCLIENTKEY}" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.adl.accessTokenEndpoint=${DLKCLITOKEPT}" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.adl.clientRootPath=${DLKCLIROPATH}" >> /usr/local/unravel/etc/unravel.properties
else
echo "One or more of your data lake storge parameter is invalid, please check your parameter file"
fi
# Adding unravel properties for Azure Cloud
echo "com.unraveldata.onprem=false" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.spark.live.pipeline.enabled=true" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.spark.appLoading.maxAttempts=10" >> /usr/local/unravel/etc/unravel.properties
echo "com.unraveldata.spark.appLoading.delayForRetry=4000" >> /usr/local/unravel/etc/unravel.properties
# Starting Unravel daemons
# uncomment below will start unravel daemon automatically but within unravel_all.sh start will have exit status=1.
# Thus we recommend login to unravel VM and run unravel_all.sh manually
# /etc/init.d/unravel_all.sh start1. Download the ARM template and parameter JSON files onto your configured Azure CLI workstation.
2. Use the Azure CLI to deploy Unravel VM using this template and parameters JSON file.
To Validate template before deployment.
az group deployment validate --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
az group deployment create --name deploymentname --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
2. When the Unravel VM creation completes, open an SSH session to the VM using your defined ssh user, and start Unravel services.
/etc/init.d/unravel_all.sh start
[INTERNAL] Step 4: ARM template for Spark2 HDinsight cluster with Unravel script actions
This ARM template allows you to create a Linux-based Spark2 HDInsight cluster and a Spark edge node. This template also runs the Unravel's Script Actions script to setup Unravel Sensors and configuration on header, worker, and edge nodes.
This ARM template uses the existing VNET, Subnet, and Storage Account on the same resource group. You need to update those values in the parameter variables to reflect your Azure environment.
A Spark edge node is a Linux virtual machine with the same client tools installed and configured as in the headnodes. You can use Spark edge node for accessing the cluster and testing/hosting your client applications.
Note
You must deploy an Unravel VM and update the script action parameters --unravel-server unravel-ip:3000 --spark-version 2.1.0
Optionally you can change the VM size of header, worker and edge nodes; and currently they are all using VM size of "Standard_D3_v2"
ARM Template | |
|---|---|
Parameter file | |
Unravel Script Action URI |
Tip
After modifying this template please validate it before applying. HDInsight cluster creation takes about 15 - 25 minutes
1. Download the ARM template and parameter JSON files into your configured Azure CLI workstation.
2. Validate template before deployment.
az group deployment validate --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
3. Use the Azure CLI to deploy Spark 2.1 cluster using this template and parameters JSON file.
az group deployment create --name deploymentname --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
1. From Azure portal, click the resource of the target Spark2 cluster under your resource group and click "Script actions".
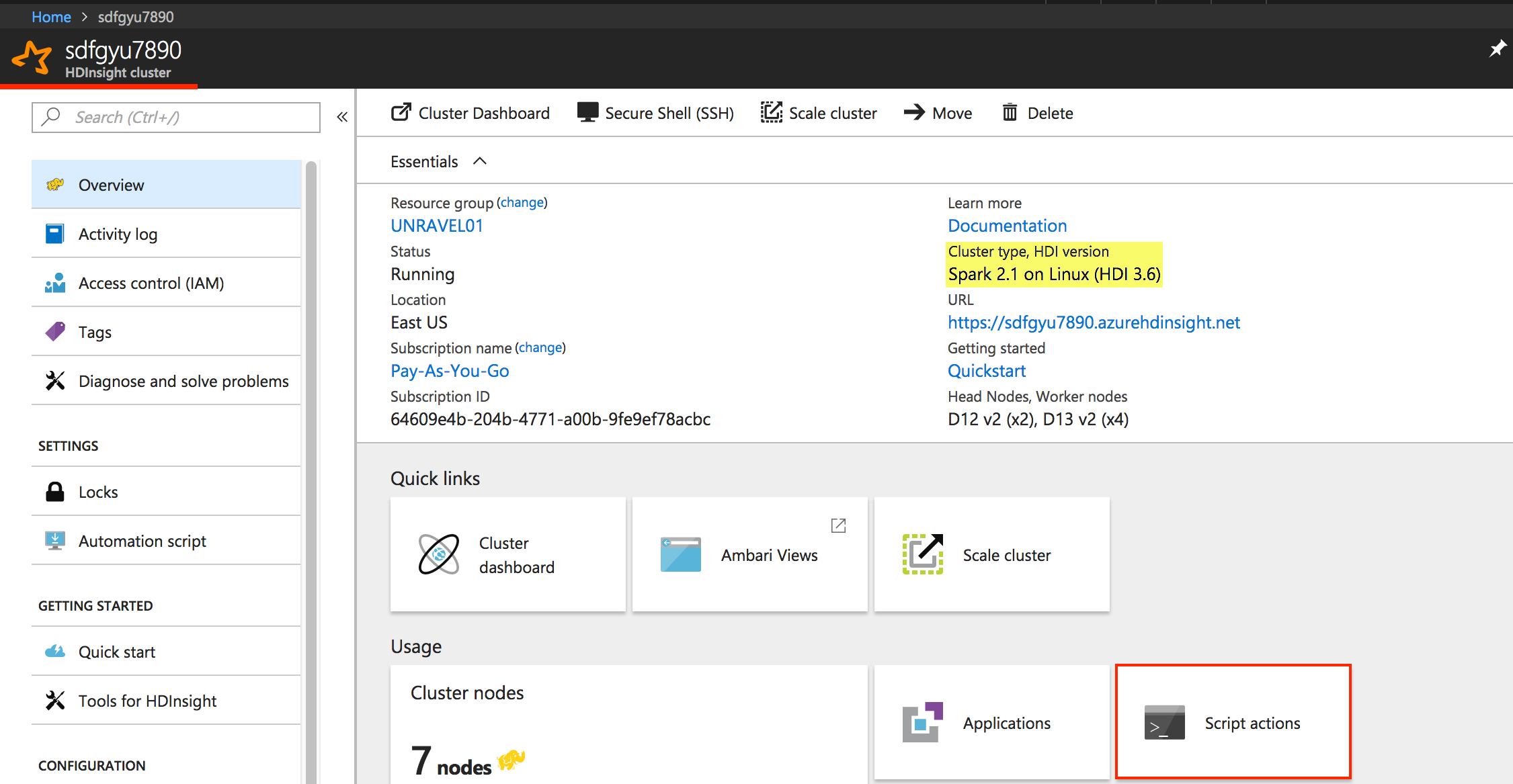 |
In Script Actions dialog box:
Click Submit new.
Select script type "- Custom"
Enter a Name for this script, e.g., "
unravel-spark-setup".Enter the script path from above e.g., https://raw.githubusercontent.com/unravel-data/public/master/hdi/hdinsight-unravel-spark-script-action/unravel_hdi_spark_bootstrap_3.0.sh
Use input parameters:
--unravel-server UNRAVEL_VM_IP_Address:30000 --spark-version 2.1.0Check the box Persist this script action to rerun when ...
Click Create.
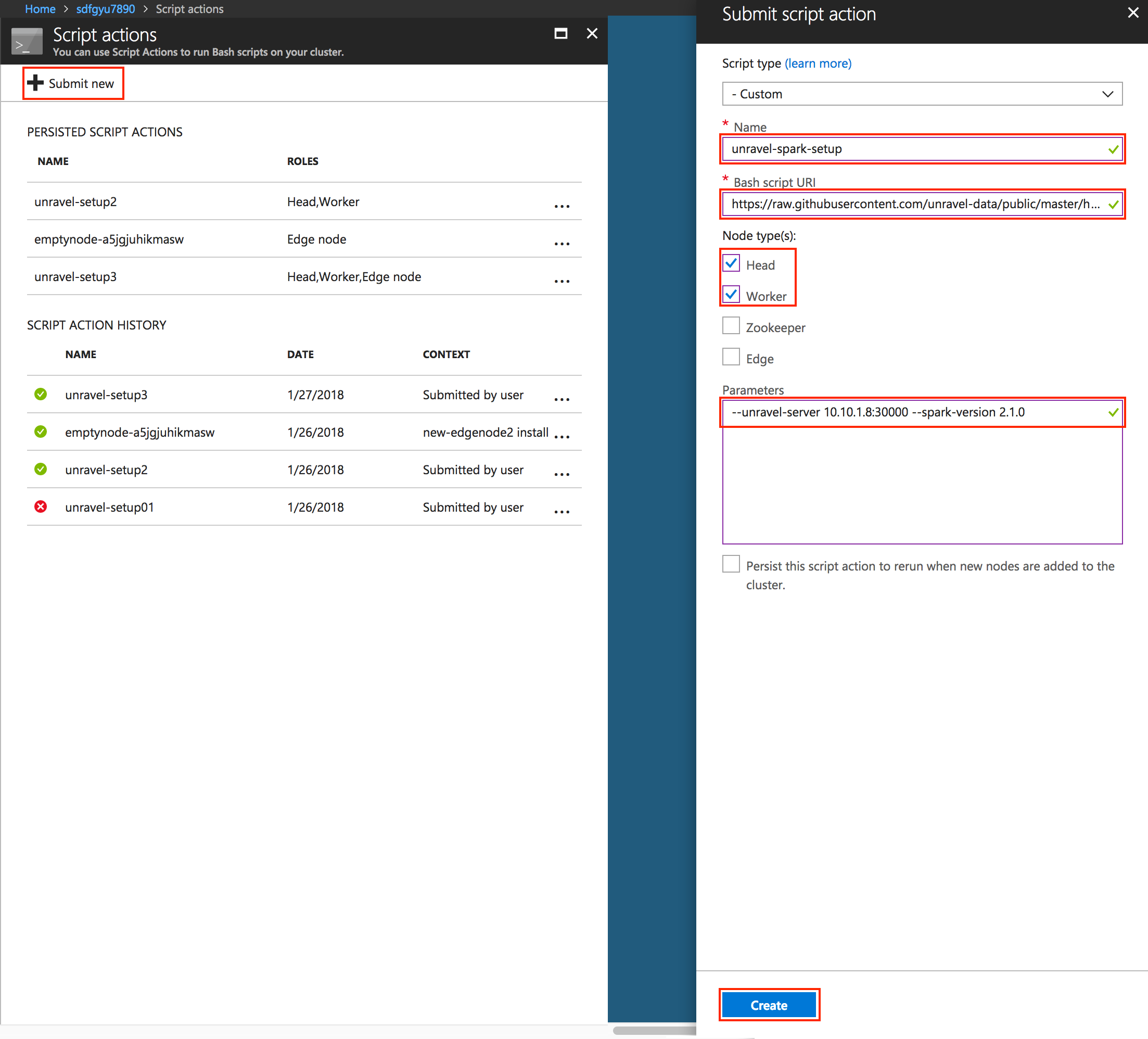 |
Warning
The checkbox for Persist this script action to rerun when ... only affects new worker nodes when scaling up the worker nodes. Checking this box does not automatically apply the Unravel Script Action script to newly added edge node from ARM template.
Tip
You can upload the unravel_hdi_bootstrap.sh script into the Azure blob storage and use the new URI path from your blob
2. Script Action validates the script and then processes it. Monitor the Azure portal until script actions has completed.
3. After completion, login to Ambari and check the Ambari task status.
ARM template | |
|---|---|
Parameter file |
In this example, an edge node will be created first. Next, it runs emptynode-setup.sh, followed by Unravel's Action script: unravel_hdi_bootstrap.sh
ARM template | |
|---|---|
Parameter file |
Note
Use of the above ARM template for edge node requires change in scriptActionUri path and application name in variables and also parameters for cluster name. Adjust the ARM templates for your setup and validate it before using.
[INTERNAL] Step 5: ARM template for Kafka cluster with Unravel script actions
This ARM template allows you to create a Linux-based Kafka cluster with Unravel setup on predefined Unravel VM. The Unravel Script Actions script for Kafka is specifically designed for Kafka cluster and needs to run on header nodes only .
This template runs Unravel's Script Actions in order to detect the Kafka cluster bootstrap servers and jmx broker nodes. It updates unravel.properties on Unravel VM with the detected values.
This ARM template uses an existing VNET, Subnet and Storage Account on the same resource group. The worker nodes in this Kafka cluster use two data disks per node.
Note
You need to deploy unravel VM and update the Script Actions parameters UNRAVEL__IP:3000.
ARM template | |
|---|---|
Parameter file | |
Unravel script action URI |
Tip
Validate the modified ARM template before applying. The HDInsight cluster creation takes about 15 - 25 minutes
1. Download the ARM template and parameter JSON files into your configured Azure CLI workstation.
2. Modify parameter file.
Change the parameter values to reflect your Azure environment, i.e., VNET, Subnet, StorageAccount, Cluster name, etc.
You can change the VM size of header, worker nodes. By default they use "Standard_D3_v2" as the VM size.
3. Validate the template before deployment.
az group deployment validate --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
4. Use Azure CLI to deploy the Kafka cluster using the template and parameters JSON file.
az group deployment create --name deploymentname --resource-group RESOURCEGROUPNAME --template-file azuredeploy.json --parameters azuredeploy.parameters.json
5. After the Kafka cluster is successfully created, the unravel Script Actions script updates the /usr/local/unravel/etc/unravel.properties on Unravel's VM with the Kafka configuration values.
The following is the example of the lines appended to unravel.properties file. The actual values will reflect your particular environment.
com.unraveldata.ext.kafka.clusters=seuguiko98003 com.unraveldata.ext.kafka.seuguiko98003.bootstrap_servers=wn0-seugui:9092,wn1-seugui:9092 com.unraveldata.ext.kafka.seuguiko98003.jmx_servers=broker1,broker2 com.unraveldata.ext.kafka.seuguiko98003.jmx.broker1.host=wn0-seugui com.unraveldata.ext.kafka.seuguiko98003.jmx.broker1.port=9999 com.unraveldata.ext.kafka.seuguiko98003.jmx.broker2.host=wn1-seugui com.unraveldata.ext.kafka.seuguiko98003.jmx.broker2.port=9999
6. Once unravel.properties file is updated, manually restart unravel_km on Unravel VM.
/etc/init.d/unravel_km restart
If you already have an existing Kafka cluster, you can apply Unravel's Kafka script via Azure portal.
1. From Azure portal, click the resource of the target Kafka cluster under your resource group and click Script Actions.
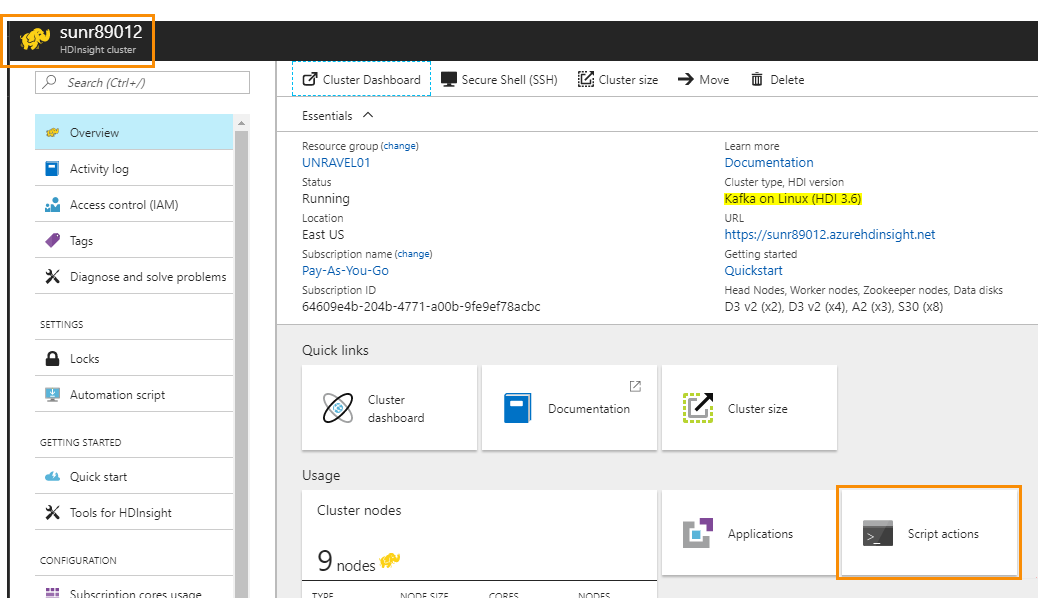 |
2. In the Script Actions dialog box:
Click Submit New
Select script type. For example,
- CustomEnter a Name for this script. For example,
unravel-kafka-setupEnter the script path from above. For example, https://raw.githubusercontent.com/unravel-data/public/master/hdi/hdinsight-unravel-kafka-script-action/unravel_hdi_kafka_bootstrap.sh
Input parameters:
UNRAVEL_VM_IP_Address:3000Check the box Persist this script action to rerun....
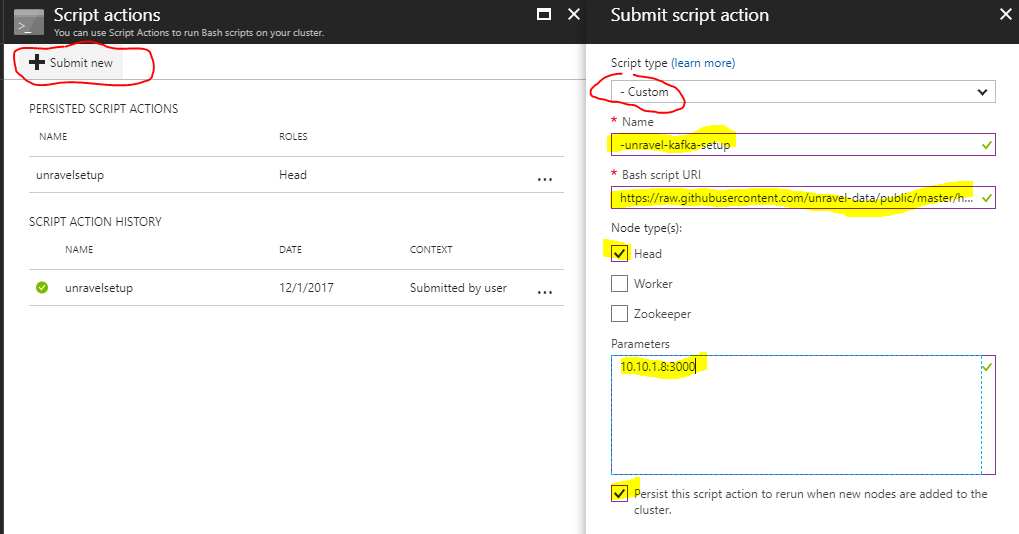 |
Tip
You can upload the unravel_hdi_kafka_bootstrop.sh script into the Azure blob storage and use the new URI path from your blob
3. Script Action validates the script and then processes it. Monitor the Azure portal until script actions has completed
4. After completion, login to Ambari of the cluster and check the Ambari task status.
4. Login to unravel VM and restart the unravel Kafka monitor daemon, unravel_km.
/etc/init.d/unravel_km restart