Configure metadata processing for Delta tables
You must schedule a job on your workspace to run the Delta table extractor job and extract the metadata into a JSON file. The metadata extractor job supports single and multiple databases.
From Databricks, schedule a job to extract metadata.
Download the
metadata_extractor_dbr_10_1.jarfile from Unravel Customer Support and upload the JAR file to your respective Databricks DBFS location.On your workspace, click Create > Job.
In the Task tab, specify the following parameters:
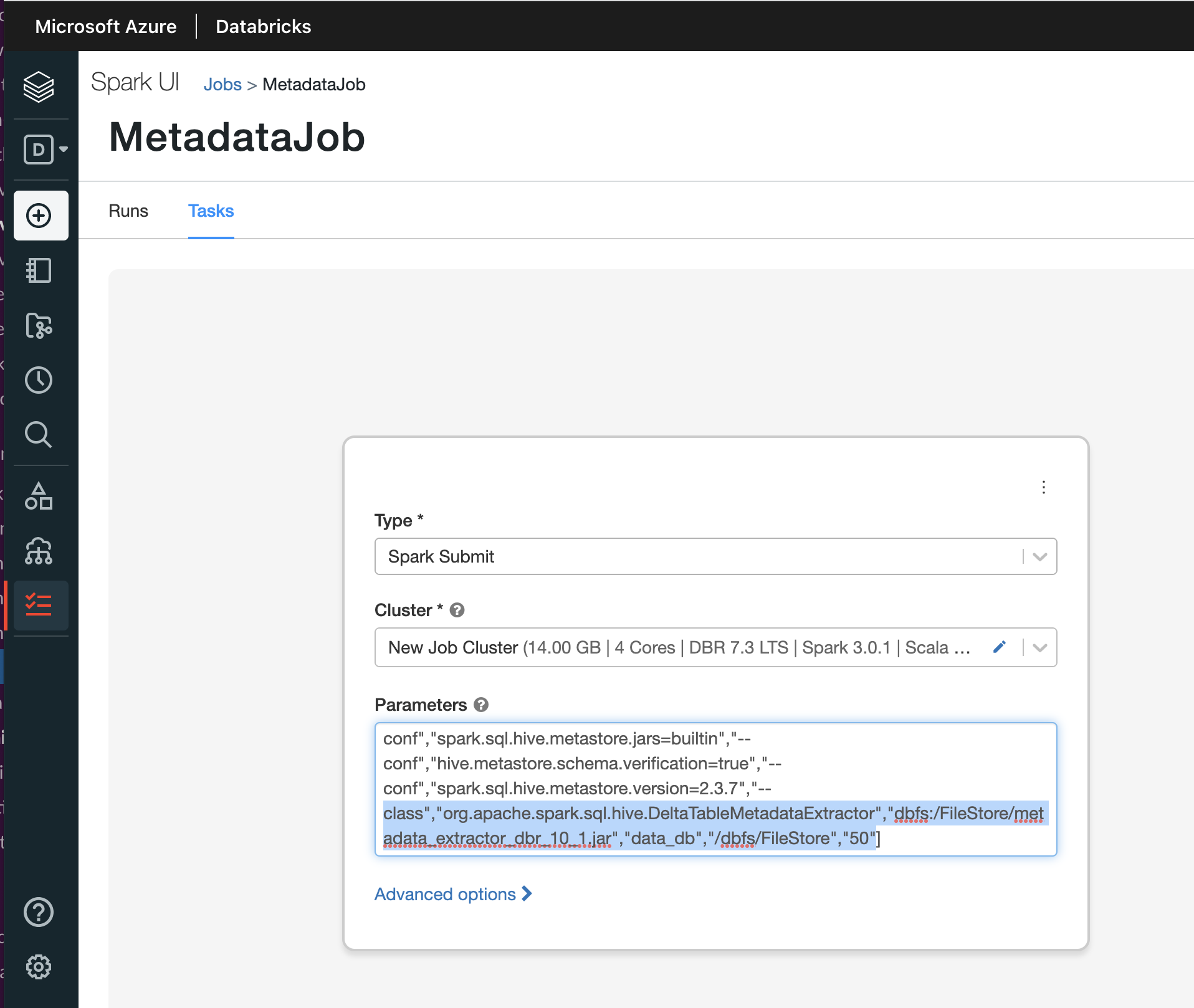
From the Type list, select Spark Submit.
From the Cluster list, select a cluster. The cluster should be of the latest (Databricks, Spark, or Scala) version. For better performance, select the cluster with the following options:
Cluster Mode
DBX runtime version
Node type
Cost (DBU/Hour)
Time
Delta Table
Single Node
10.4
Standard_E8_v3(64,8)
2
50 minutes
10000
Single Node
10.4
Standard_E16_v3(128,16)
4
2.5 hours
25000
In the Parameters text box, specify the following parameters as mentioned in the example:
Example for a single database:
["--class","org.apache.spark.sql.hive.DeltaTableMetadataExtractor","dbfs:/FileStore/metadata_extractor_dbr_10_1.jar","customer_db","/dbfs/FileStore/delta/","25000"]
Parameters
Description
"dbfs:/FileStore/metadata_extractor_dbr_10_1.jar"
Specify the location of the JAR file that you uploaded to DBFS in Step 1.
For a single database name:
"customer_db"
For multiple database names:
"customer_db1","customer_db2","customer_db3"
Specify a valid database name. (Mandatory)
Specify multiple database names in a comma-separated value.
Specify all database names using the
ALL_DBparameter.
After you specify multiple database names or the
ALL_DBparameter, the following actions are triggered:A separate JSON file is created for each database.
Databases are processed until the Delta table max counter is reached. The maximum Delta table limit value processed by the metadata extractor job is 25,000 across all databases. If the Delta table count is less than 25,000, then the job processes all the delta tables.
Databases are processed based on the order of database names specified in the database name parameter.
"
<path-of-the-output-directory>"Specify the output directory path where the metadata files are stored. (Optional)
If you do not specify the path, by default, the metadata files are stored in the
/dbfs/FileStore/deltadirectory."25000"
Specify the number of Delta tables. (Optional) You can extract up to 25,000 delta tables metadata in a single job.
Note
You cannot extract more than 25,000 delta tables in a database. For example, if the database contains 30,000 delta tables, then only the first 25,000 delta tables are processed, and the remaining are ignored.
A metadata file is generated in DBFS.
Set up Unravel to process Delta table metadata
Copy the metadata file from DBFS to any location in Unravel node.
Restart the table_worker daemon to synchronize all Delta tables to the Unravel database and Elasticsearch index.
<Unravel/installation/directory>/manager restart table_workerRun the
delta_file_handoff.shutility.<Unravel Installation directory>/unravel/manager run script delta_file_handoff.sh </path/to/metadata file>The utility processes a single file or a directory path containing multiple files according to the specified parameters in the metadata extractor job. After successful processing, a message is displayed.
Note
If Delta table processing fails, check the following error logs in the
delta_file_handoff.logfile located at/opt/unravel/logs/.INFO table.DeltaTableProcessing: DeltaTableProcessing.start() => Delta tabel processing has started. WARN Cluster info is missing for metastoreId: ERROR Failed to read file ERROR Failed to parse json data. WARN Unable to update table for table id
Log in to the Unravel UI, navigate to Data page > Tables, and verify that the Storage Format column contains the Delta value for the Delta tables listing.