Table Access report
Use the Table Access Report to extract and review Hive, Impala, and Spark application data. The report generates CSV files and an HTML report. It extracts Hive and Impala applications into hive_impala_apps.csv and Spark applications into spark_apps.csv based on a specified time range.
Key Features
Query Performance Analysis: Identify slow queries, track execution trends, and analyze resource allocation.
Data Access Patterns: Determine frequently accessed tables for indexing and partitioning strategies.
Resource Utilization & Optimization: Analyze data read/write volumes to optimize storage and processing.
Query Failure & Debugging: Identify and troubleshoot failed or recurring problematic queries.
Generating a New Report
The following are the mandatory fields for generating a table access report:
Report Name: Name the report.
Retention*: Define the retention period.
Look Back: Set the time range for data extraction.
Email ID: Provide an email address for mail notifications (optional).
For details on the other fields, refer to the following section:
Using the Report
After specifying the inputs, the system creates two CSV files:
hive_impala_apps.csv
Contains combined details of Hive and Impala applications.
spark_apps.csv
Contains details of Spark applications.
The following fields are available providing an overview of query execution details in a Hive/Impala environment:
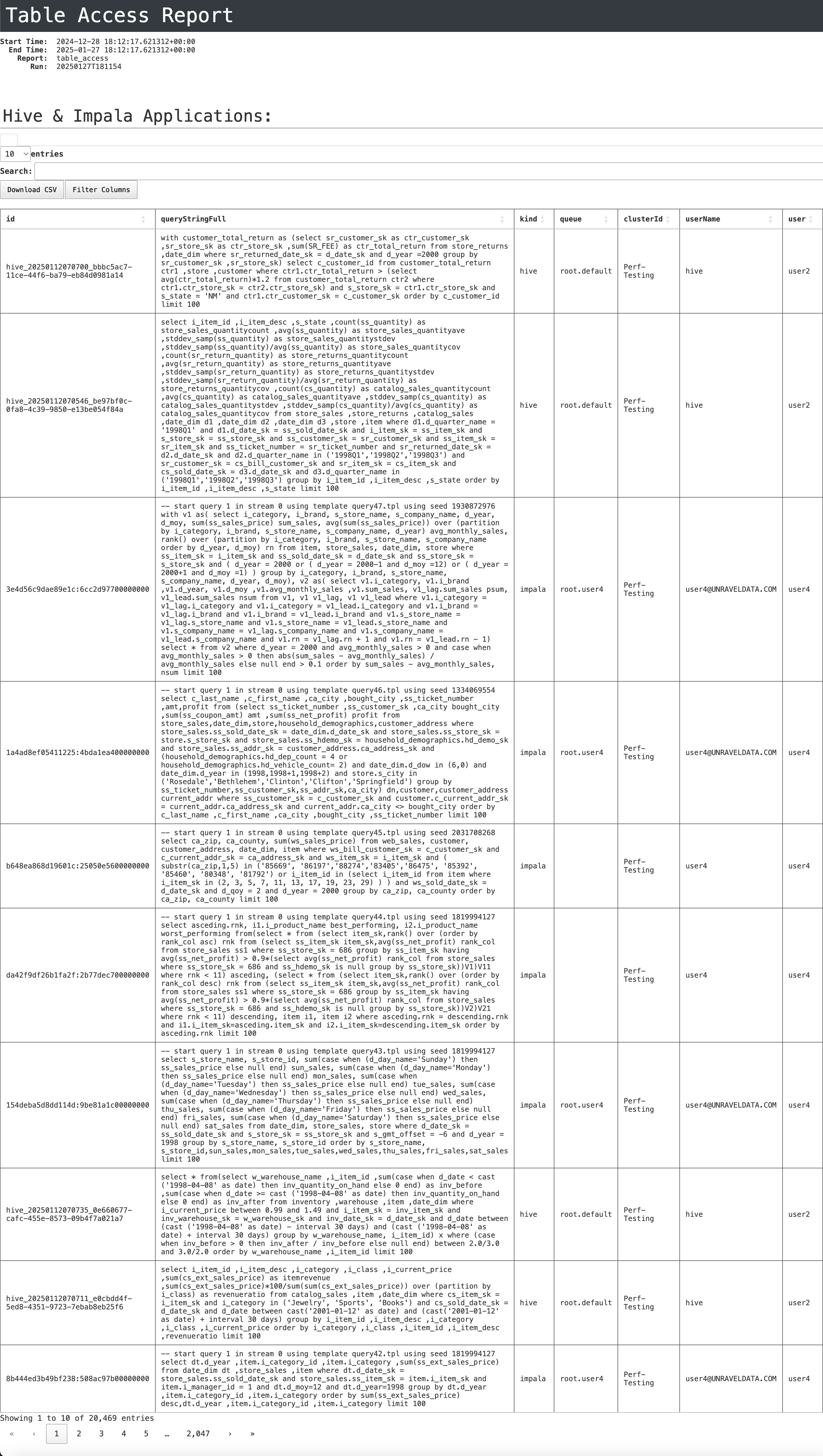
id : A unique identifier for each query.
queryStringFull : The full SQL query executed.
kind : The type of query engine used (e.g., Hive or Impala).
queue : The queue used for executing the query.
clusterId : The cluster identifier where the query was executed.
userName : The user who executed the query.
user : A more detailed user identifier.
startTime : The timestamp when the query execution started.
finishedTime : The timestamp when the query execution finished.
Duration(Seconds) : The total time taken for query execution in seconds.
inputTables : The list of tables read by the query.
outputTables : The list of tables written to by the query.
totalDfsBytesRead : The total amount of data read from the distributed file system (DFS) in bytes.
totalDfsBytesWritten : The total amount of data written to the DFS in bytes.
status : The final status of the query execution