Connecting Unravel Server to a new Dataproc cluster
This topic explains how to set up and configure your Dataproc cluster so that Unravel can begin monitoring jobs running on the cluster.
Assumptions
The GCE instance for Unravel Server has been created.
Unravel services are running.
The firewall rules on the GCE allow traffic to/from Dataproc cluster nodes on TCP port 3000.
The Unravel GCE instance and Dataproc clusters allow all outbound traffic.
The nodes in the Dataproc cluster allow all traffic from the Unravel GCE. This implies either one of the following configurations:
The DataProc cluster is on a different VPC, and you've configured VPC peering, route table creation, and updated your Firewall policy.
The DataProc cluster is on a different VPC, and you've configured VPC peering, route table creation, and updated your Firewall policy.
Network ACL on VPC allows all traffic.
Connect to a new DataProc cluster
Follow the steps below to run Initialization actions, unravel_dataproc_init.py, on all nodes in the cluster. The bootstrap script makes the following changes:
On the server/parent node:
On Hive clusters, it updates
/etc/hive/conf/hive-site.xml.On Spark clusters, it updates
/etc/spark/conf/spark-defaults.conf.It updates
/etc/hadoop/conf/mapred-site.xml.It updates
/etc/hadoop/conf/yarn-site.xml.If Tez is installed, it updates
/etc/tez/conf/tez-site.xml.It installs and starts the
unravel_esdaemon in/usr/local/unravel_es.It installs the Spark and MapReduce sensors in
/usr/local/unravel-agent.It installs the Hive Hook sensor in
/usr/lib/hive/lib/.
On all other nodes:
It installs the Spark and MapReduce sensors in
/usr/local/unravel-agent.It installs Hive sensors in
/usr/lib/hive/lib.
Be sure to substitute your specific bucket location for my-bucket.
Download Unravel's bootstrap script,
unravel_dataproc_init.pyusingcurlorgsutil.curlcurl https://storage.cloud.google.com/unraveldata.com/unravel_dataproc_init.py -o /tmp/unravel_dataproc_bootstrap.py
gsutilgsutil cp gs://unraveldata.com/unravel_dataproc_init.py /tmp/unravel_dataproc_init.py
Upload the bootstrap script to a Google Cloud Storage Bucket.
Permissions needed
You need the write access to the Cloud Storage bucket that you want to upload the init actions script to. In addition, the GCP account you use to create the Dataproc cluster must have read access to the init action script to execute its directives.
Use
gsutilto upload the init action script to the default Dataproc logging bucket.gsutil cp unravel_dataproc_init.py gs://
my-bucket/unravel_dataproc_init.pyIn the GCP console, select the Dataproc services and click Create cluster.
In Hardware section:
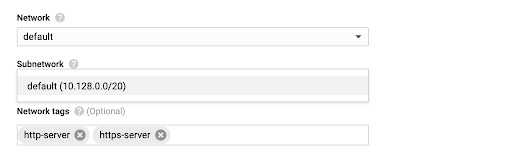
Set Network and VM Subnet to the cluster's VPC and subnet.
The firewall rule of the subnet you specify must have access to the Unravel GCE node.
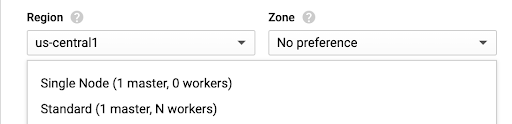
Select the required configuration of the cluster, with cluster mode being Single node/Standard.
Modify the instance type and enter the desired instance count for worker and preemptible worker nodes
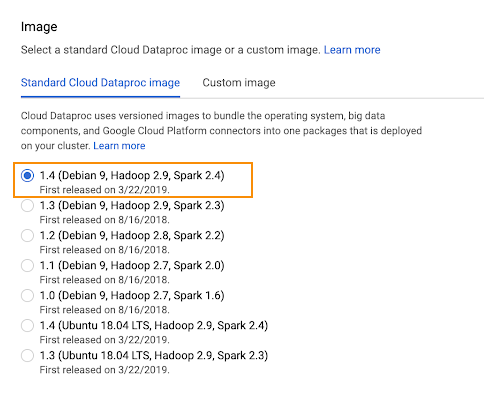
Select the Image 1.4/1.3 from Standard Cloud Dataproc image.
Provide the Network Options such as the VPC, subnet as specified in the prerequisites.
Add the Initialization actions and Metadata to connect your Dataproc cluster to the Unravel node
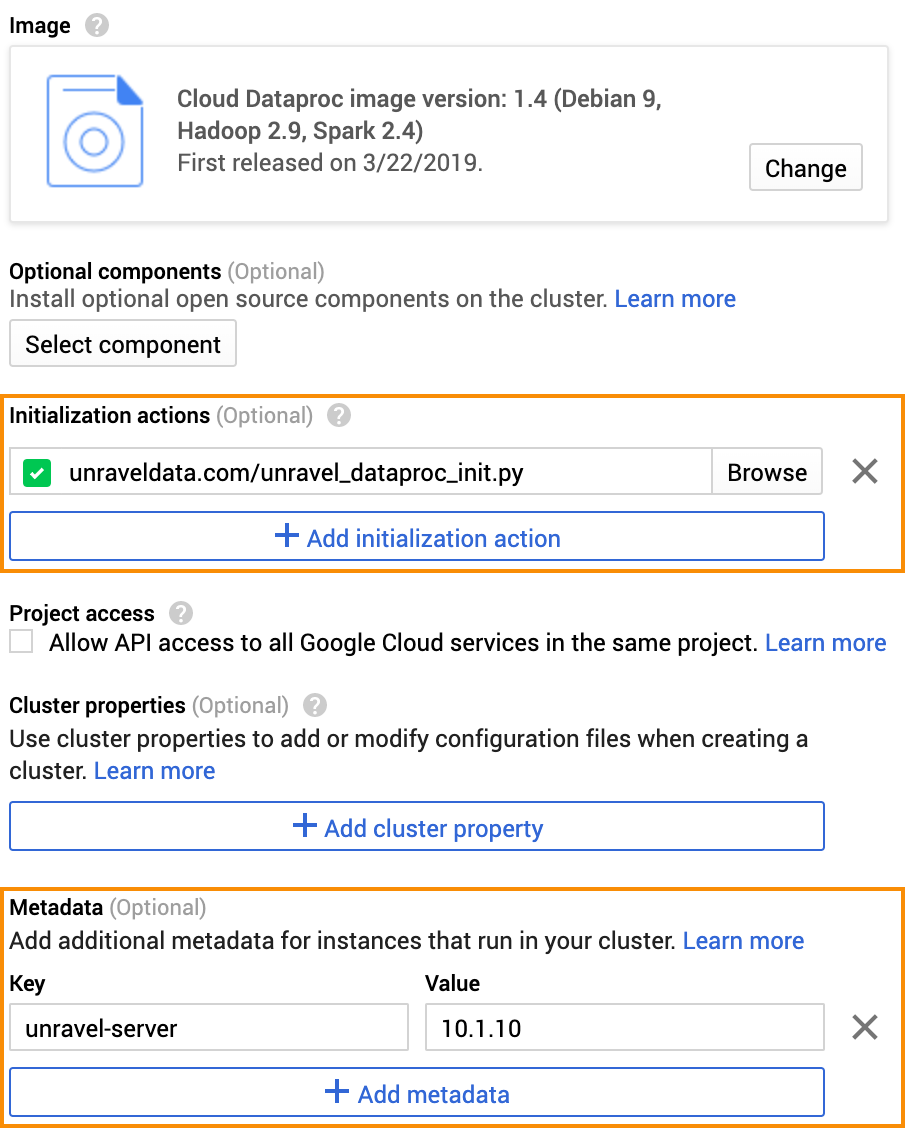
You can specify script arguments in the Metadata section.
Settings
Value
Script location
Script location
gs://my-bucket/unravel_dataproc_init.pyOptional arguments
metrics-factor interval:Specifies the interval at which Unravel sensors push data from the Dataproc cluster nodes to Unravel Server. interval is in units of 5 seconds. In other words, a value of 1 means 5 seconds, 2 means 10 seconds, and so on. Default: 1.all:Enables all sensors, including the MapReduce sensor.disable-aa:Disables the AutoAction feature.enable-am-polling:Enables "application master" metrics polling for AutoActions.hive-id-cachenum-jobs:Maximum number of jobs you expect to have on the cluster. Default: 1000.Click Create Cluster.
Sanity check
After you connect the Unravel GCE to your Dataproc cluster, run some jobs on the Dataproc cluster and monitor the information displayed in Unravel UI (http://unravel_VM_node_public_IP:3000).