Integrating with Informatica Big Data Management
Informatica Big Data Management (BDM) suite enables enterprises to deploy advanced data management capabilities, including data ingestion, data quality, data masking, and stream processing. BDM provides a graphical user interface for generating ETL mappings (jobs) and workflows for various frameworks, such as Spark, Hive on MapReduce, or Hive on Tez. You install BDM on an edge node in your Hadoop cluster, and use it to create jobs and workflows that ingest data into your cluster. The BDM interface allows you to construct jobs graphically, by connecting data sources to mappings to data destinations; BDM creates Hive or Spark queries for you, which removes the need for you to know Hive or Spark programming. However, while a non-programmatic interface is convenient, the jobs BDM generates might need tweaking to improve their performance or to meet your SLAs. Optimizing these BDM-generated data workflows can be complex and a resource drain for many customers. This is where Unravel comes in. The Unravel UI shows more information for each BDM job or workflow than YARN or your cluster manager does.
This topic explains how to connect Unravel to your BDM jobs and workflows, so that Unravel can provide operational insights, recommendations, and automation to maximize their performance.
You've already installed Informatica BDM on an edge node in your cluster.
You've already installed Unravel Server on an edge node in your cluster.
Your cluster is on-premises CDH/HDP/MapR, or cloud-based Amazon EMR or Microsoft Azure HDInsight.
Setting properties in each mapping and workflow
These steps enable Unravel UI to display your BDM workflows and jobs.
Log into the BDM graphical user interface.
Select a mapping.
Open the mapping's Properties view.
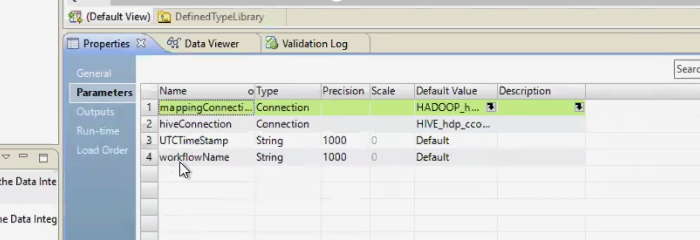
In the Parameters tab, create two parameters:
Create a parameter named UTCTimeStamp of Type string, with Precision set to 1000, Scale set to 0 and Default Value set to Default.
Create a parameter named workflowName of Type string, with Precision set to 1000, Scale set to 0 and Default Value set to Default.
Set up workflow tags.
In the Run-time tab, map the two parameters you created to Unravel's workflow properties:
Expand the Hadoop label and edit Runtime Properties:
For Hive-on-Spark, create the Unravel property spark.unravel.workflow.name; for Hive-on-MR or Hive-on-Tez, create unravel.workflow.name. Set the Unavel property's value to the BDM job's workflowName parameter.
For Hive-on-Spark, create the Unravel property spark.unravel.workflow.utctimestamp; for Hive-on-MR or Hive-on-Tez, create unravel.workflow.utctimestamp. Set the Unavel property's value to the BDM job's UTCTimeStamp parameter.

Log into the BDM graphical user interface.
Select a workflow.
Open the workflow's Properties view.
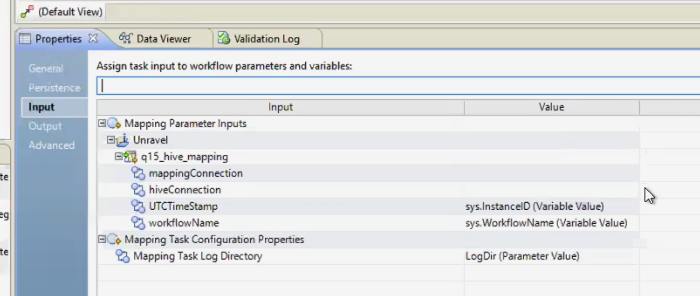
In the Input tab, set values for the two parameters you created in each mapping:
Click Mapping Parameter Inputs | Unravel.
Set UTCTimeStamp to the system variable
sys.InstanceID.Set workflowName to the system variable
sys.WorkflowName.
Enabling additional instrumentation from BDM
To get even more instrumentation from BDM, follow these steps on the BDM host --in other words, the edge node that's running BDM.
Log into your BDM console as administrator.
In the BDM console, select Manage | Connections.
Put Unravel's Hive Hook JAR in AUX_CLASSPATH.
In Domain Navigator, expand | Domain | ClusterConfigurations | HADOOP_hdp_cco.
Edit Hive Pushdown Configuration:
Set Engine Type to Hive or Tez. Set Advanced Properties to: AUX_CLASSPATH=${AUX_CLASSPATH}:/usr/local/unravel_client/unravel-hive-1.2.0-hook.jar
Deploy Unravel's Spark JAR.
In Domain Navigator, expand | Domain | ClusterConfigurations | HADOOP_hdp_cco.
Under Spark Configuration, set Spark Event Log Directory to
hdfs:///spark2-history/
Under Spark Configuration, append Unravel's Spark sensors to the following properties in Advanced Properties:
spark.unravel.server.hostport=
unravel-host:4043 spark.driver.extraJavaOptions=-javaagent:path-to-btrace-agent.jar=config=driver,libs=spark-version spark.executor.extraJavaOptions=-javaagent:path-to-btrace-agent.jar=config=executor,libs=spark-version
Connect to the Hive metastore to enable Unravel's Hive hooks.
In Domain Navigator, expand | Domain | ClusterConfigurations | your deployment, such as HDP_CCO for HDP| hive_site_xml, and click Edit.
In the Edit hive_site_xml dialog, set the following properties:
com.unraveldata.hive.hook.tcp = truecom.unraveldata.hive.hdfs.dir = /user/unravel/HOOK_RESULT_DIRcom.unraveldata.host = unravel-hosthive.exec.pre.hooks = com.unraveldata.dataflow.hive.hook.unravel hive.exec.post.hooks = com.unraveldata.dataflow.hive.hook.unravel hive.exec.failure.hooks = com.unraveldata.dataflow.hive.hook.unravel In Domain Navigator, expand | Domain | ClusterConfigurations | your deployment, such as HDP_CCO for HDP| tez_site_xml, and click Edit.
In
tez.am.launch.cmd-opts, add a space and append this line to the existing values:-javaagent:/usr/local/unravel-agent/jars/btrace-agent.jar=libs=mr,config=tez -Dunravel.server.hostport=
unravel-host:4043In
tez.task.launch.cmd-opts, add a space and append this line to the existing values:-javaagent:/usr/local/unravel-agent/jars/btrace-agent.jar=libs=mr,config=tez -Dunravel.server.hostport=
unravel-host:4043
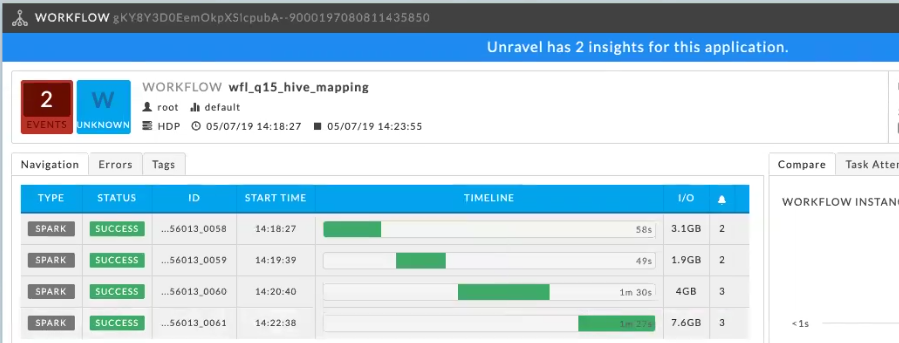
Viewing BDM jobs and workflows in Unravel UI
In Unravel UI, look at Applications | Workflows. For more information, refer to the product documentation.
 |