Microsoft Azure Databricks (Marketplace)
Unravel for Azure Databricks provides Application Performance Monitoring and Operational Intelligence for Azure Databricks. It is complete monitoring, tuning, and troubleshooting tool for Spark Applications running on Azure Databricks.
Deploying Azure Databricks from Azure Marketplace
This topic describes how to launch an Unravel server in Azure from the Azure Marketplace, set up the following configuration, and have your Azure Databricks workloads monitored by Unravel.
 |
The following steps show you how to get Unravel for Azure Databricks up and running via the Azure Marketplace.

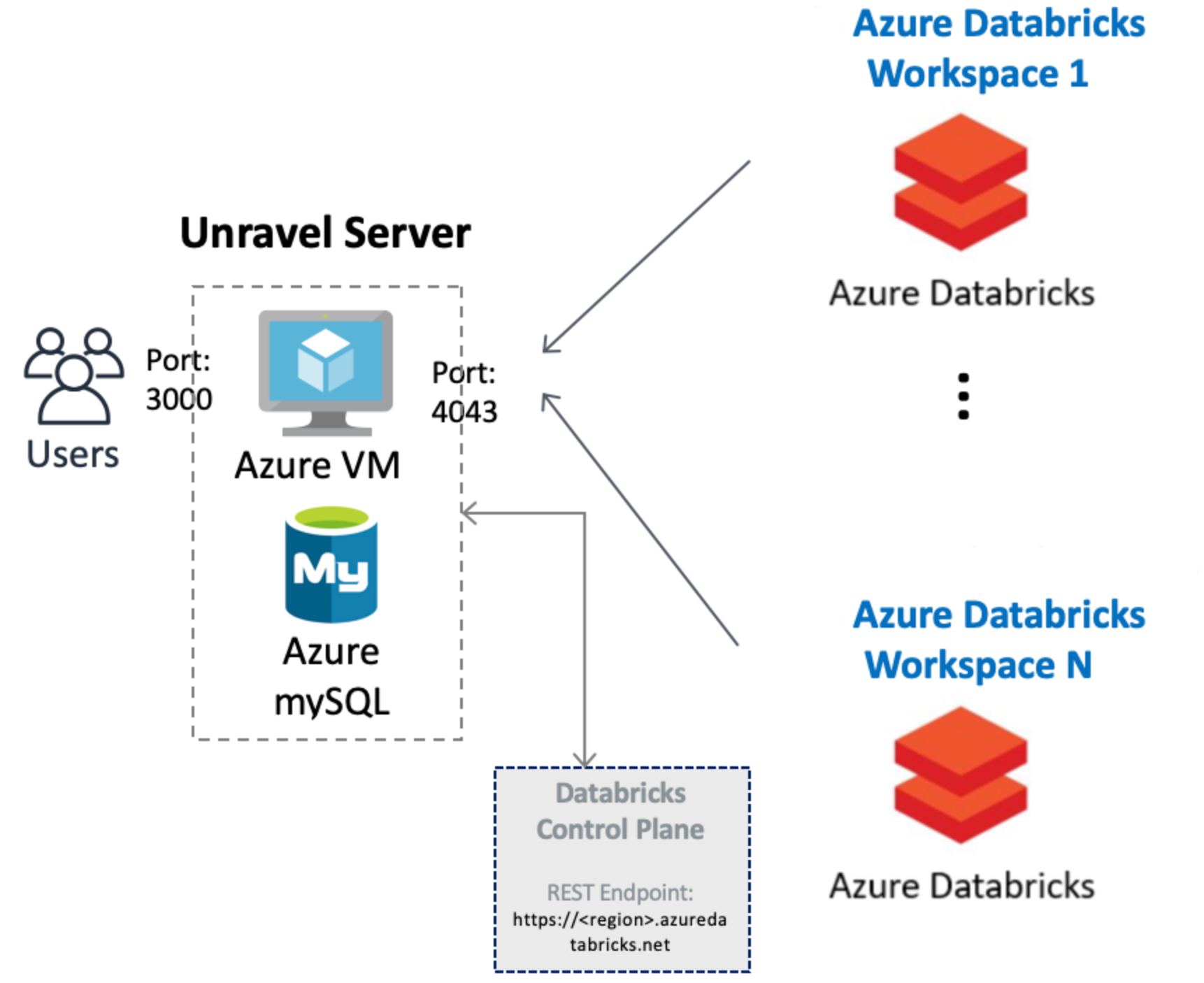
Unravel for Azure can monitor your Azure VM Databricks with the following VNET peering options. Follow the options based upon your specific setup.
You must have the following ports open:
Important
Both ports are initially opened to the public, you can restrict the access as needed.
Port 4043: Open this port to receive traffic from the workspaces so that Unravel can monitor the Automated (Job) Clusters in your workspaces.
Port 3000: Open this port for HTTP access for accessing the Unravel UI.
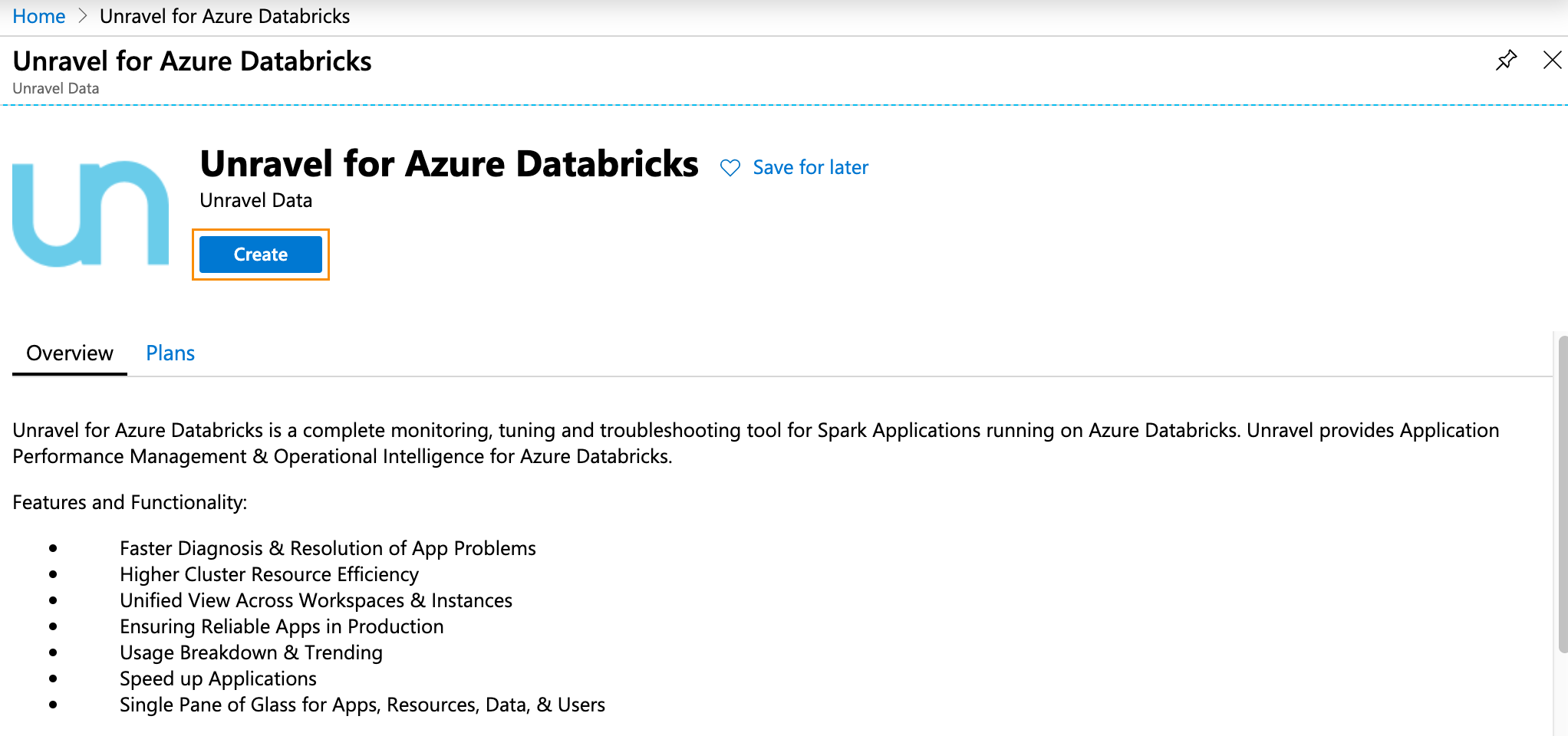
Search Unravel for Azure Databricks in the Azure Marketplace.
In the Create this app in Azure modal, click Continue. You are directed to the Azure portal.
In the portal, click Create to begin the Unravel server setup.
In Home > Virtual Machine > Create step through the tabs completing the information. Make sure to keep your requirements and the background criteria in mind when completing the information.
In the Basics tab (default) enter the following.
Project Details
Subscription: Choose the applicable subscription.
Resource group: Create a new group or choose an existing one.
Instance Details
Region: Select the Azure region.
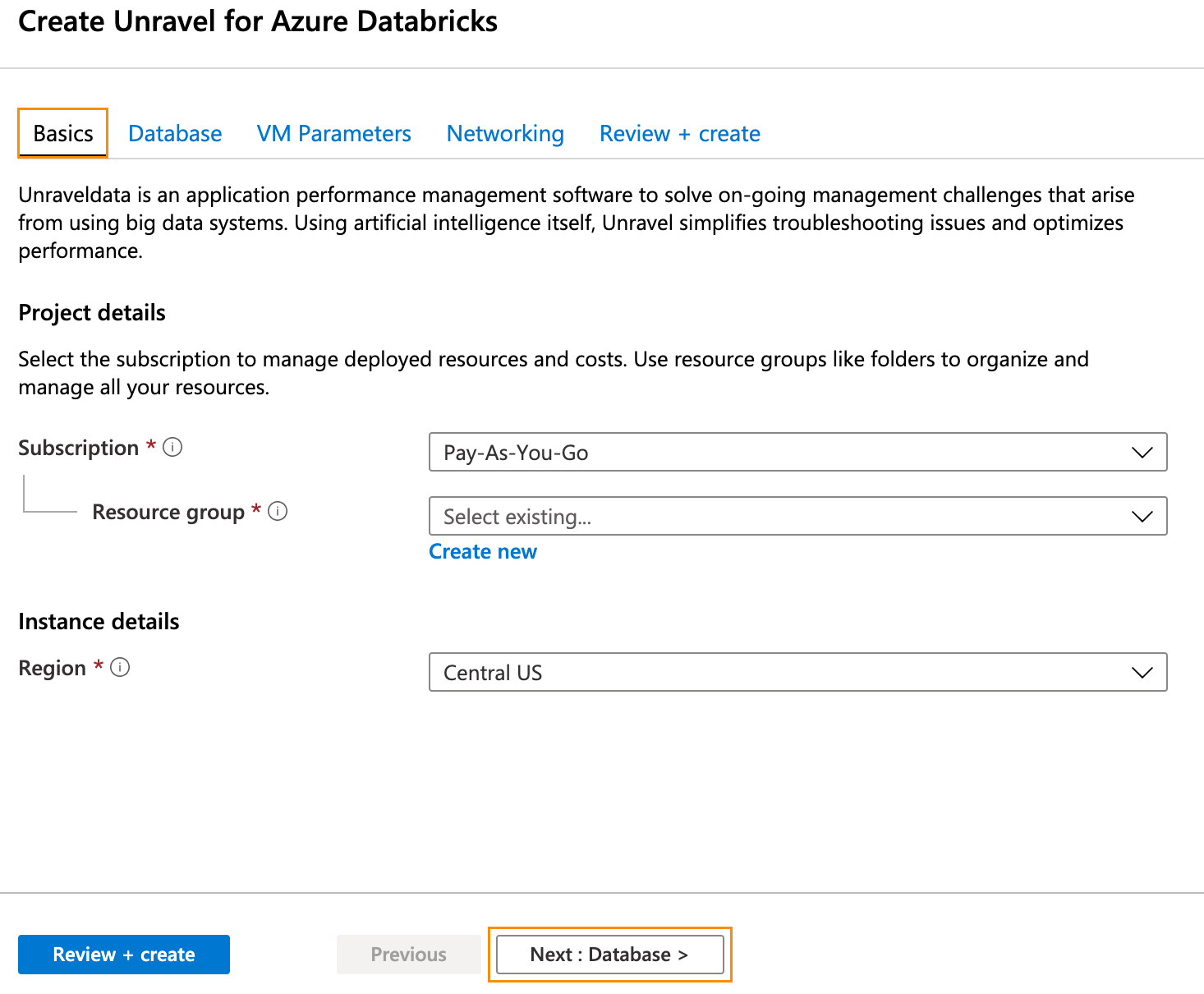
Click Next: Database > and complete the Database information. Click Next: VM Parameters >.
In the VM Parameters tab enter the following information.
Size: Click Change Size to select your desired size. Memory-optimized image with at least 128 GB memory is recommended.
Admin Username: VM admin username.
Password: VM admin password.
Data Disk Size GB: Enter your disk size.
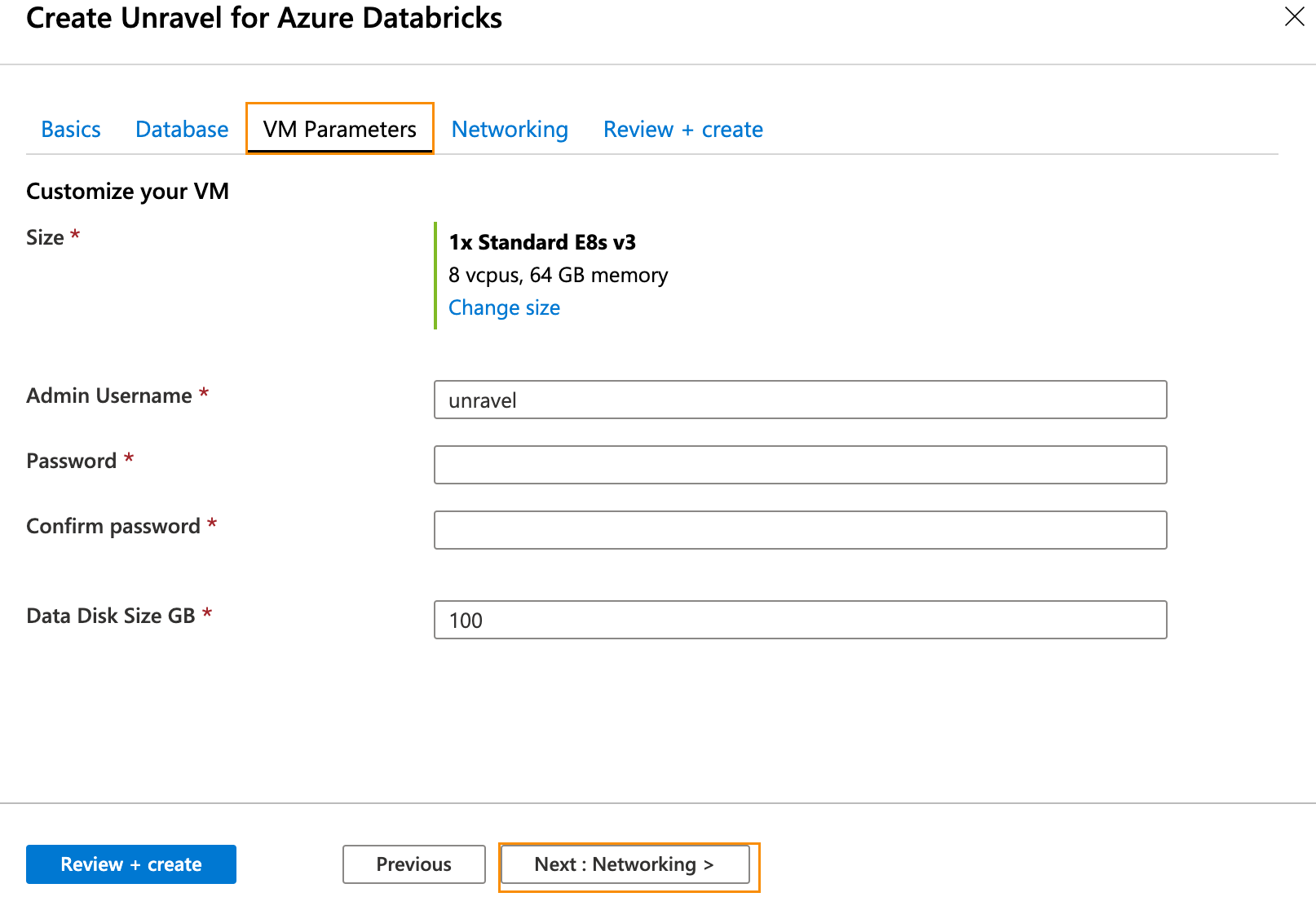
Click Next: Networking >. In the Networking tab and enter the following information:
Public IP Address: Create an address or choose an existing one.
Attach Public IP to Unravel VM: Set to
true.
Important
If you set it to
falseensure you have a valid method to connect to Unravel UI on port 3000.
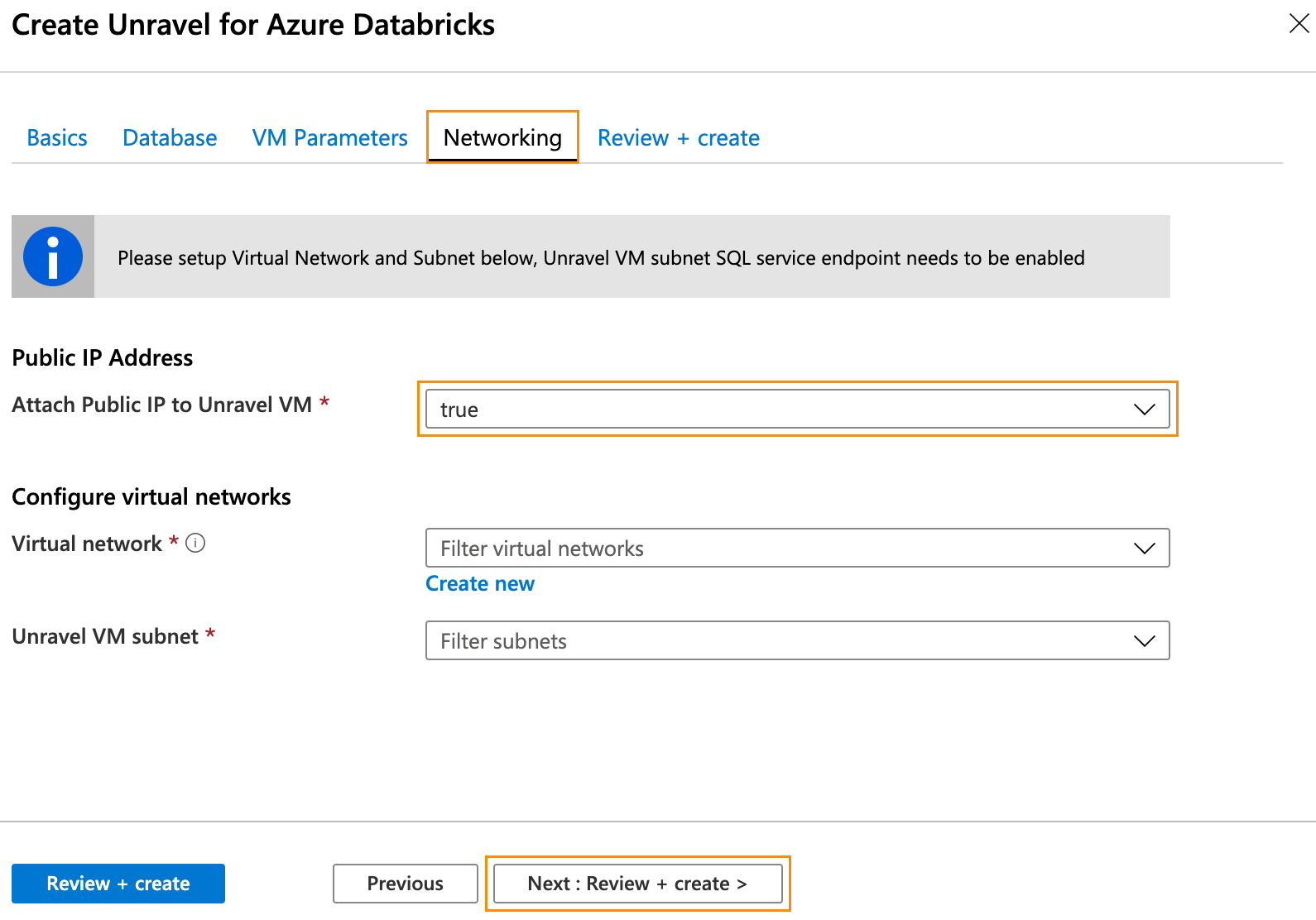
Click Next: Review + Create. After you have reviewed and verified your entries, click Create for your deployment to be created. Note your resource group.
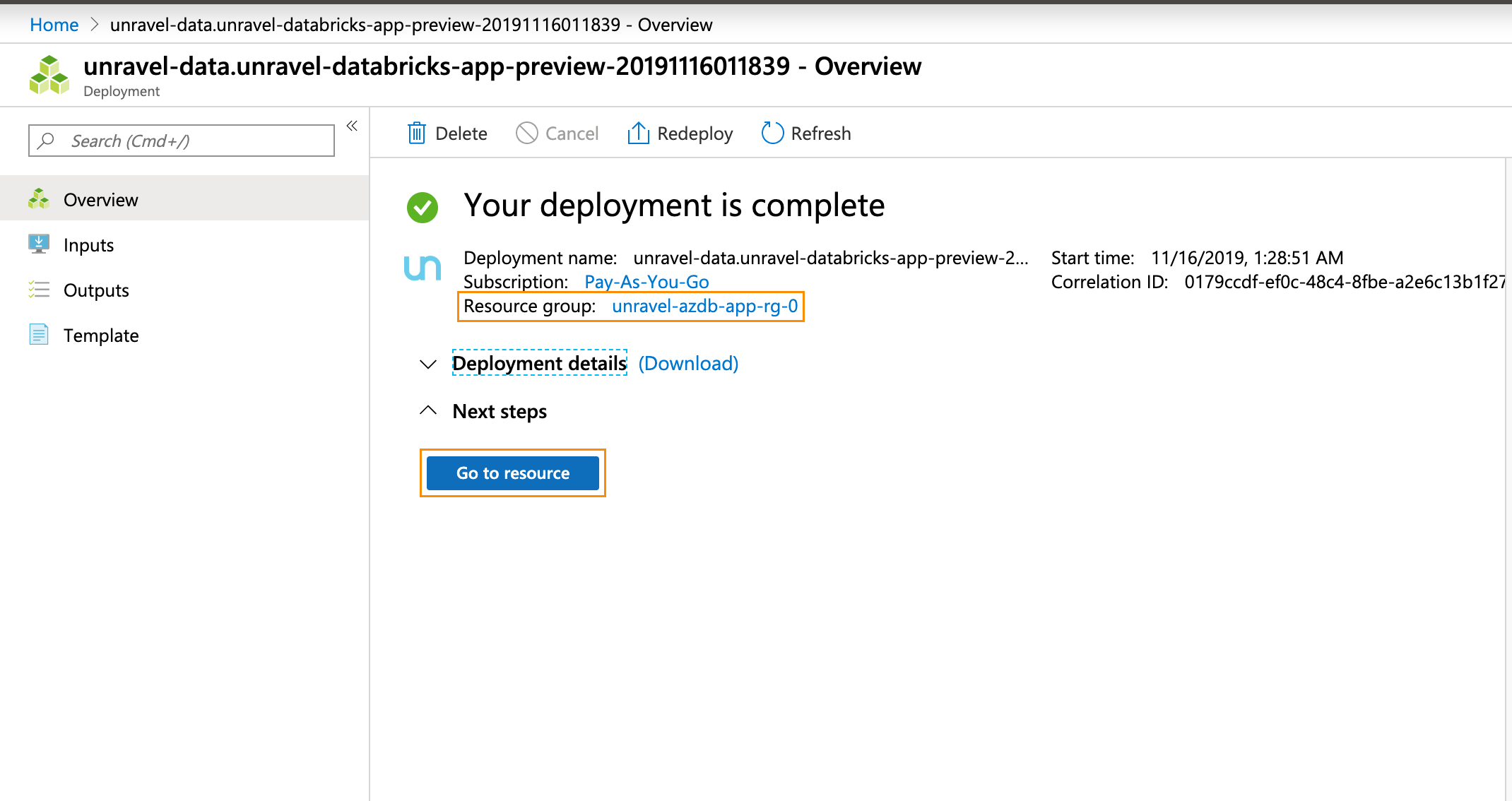
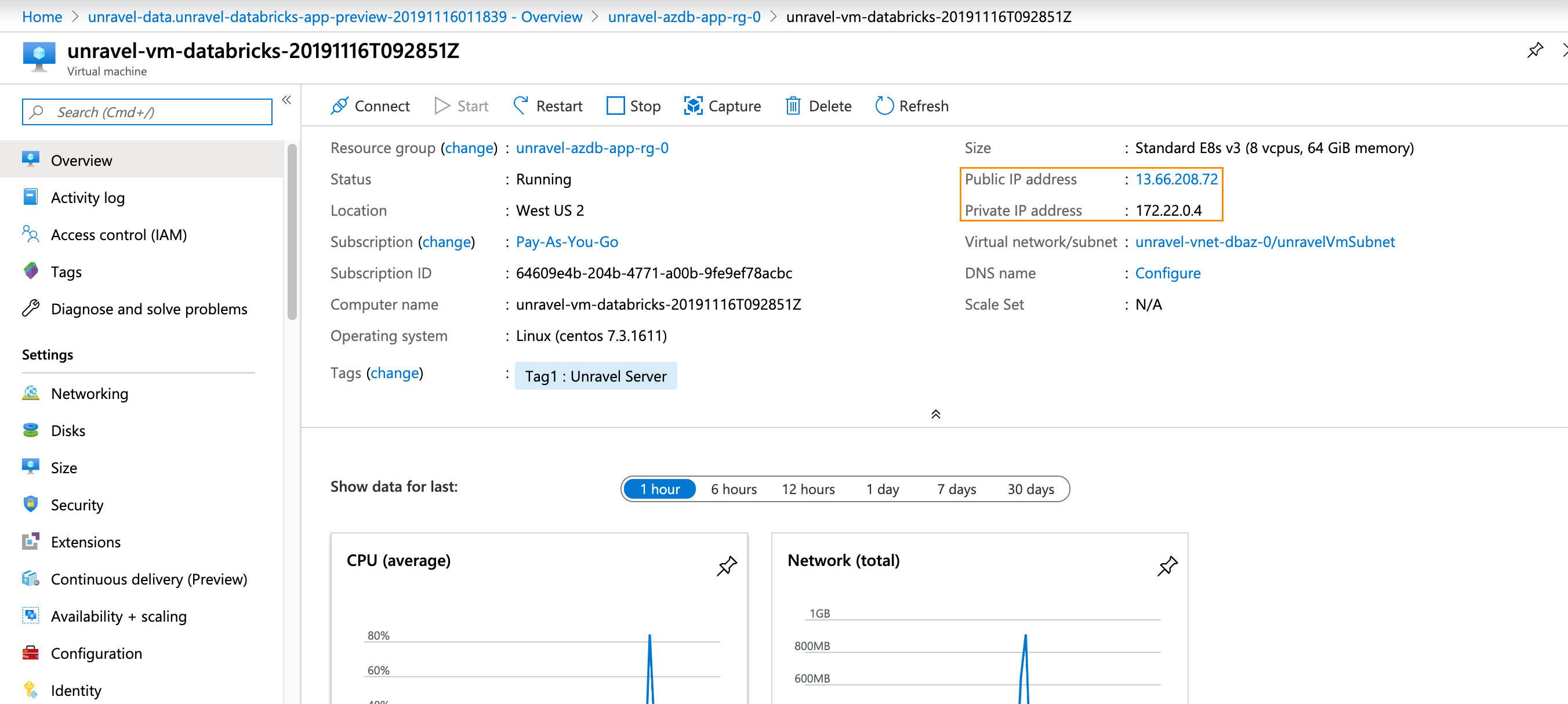
Click Go to Resource. Find the details of the Unravel VM.
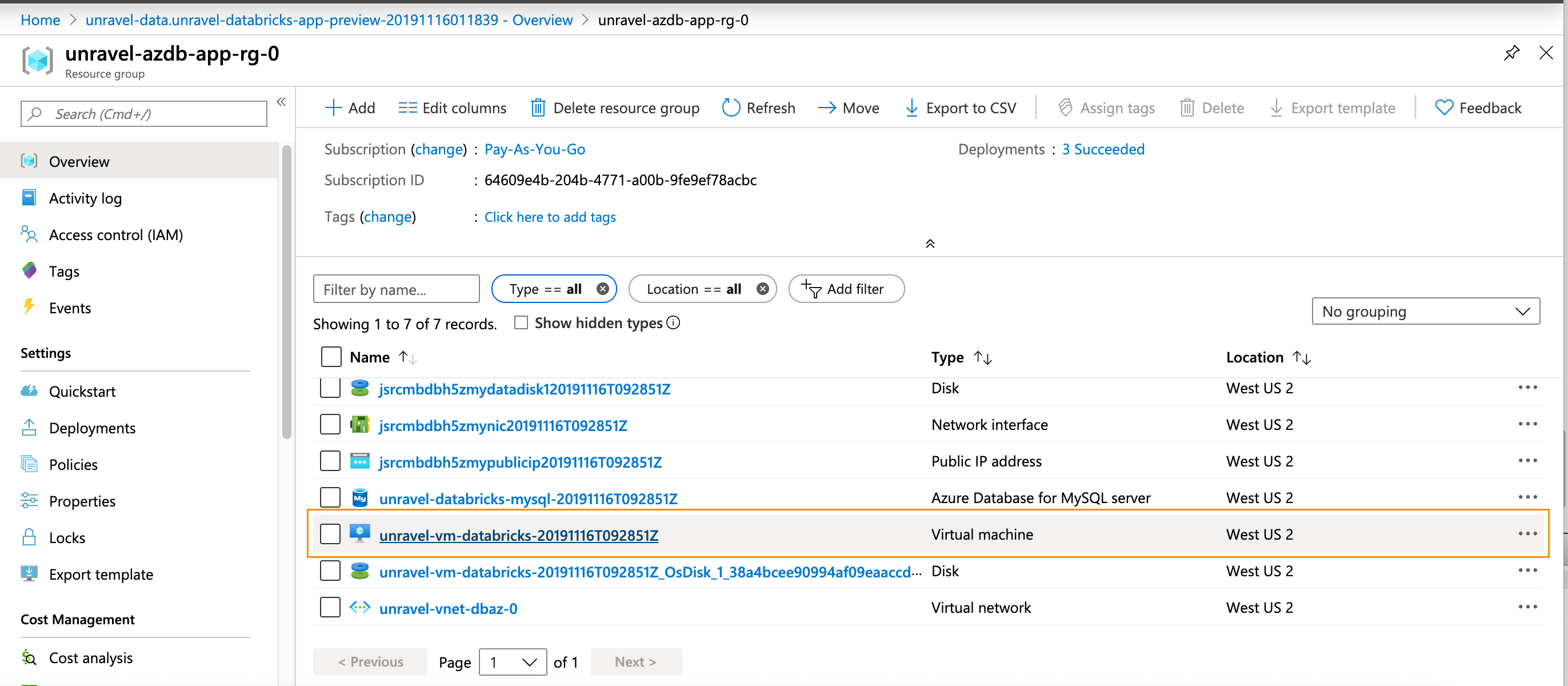
Click on the
VMnameto bring it up in the Azure portal.Notice
For the remainder of the configuration, it is assumed that you have attached a public IP address to the Unravel VM. If that is not the case, you can modify these instructions to suit your deployment.
Make a note of the Public and Private IP address.
Log into the Unravel server via a web browser. Enter either http://
<hostname>or <IP of the VM>:3000. Log in using the Adminusernameandpasswordentered in the VM Parameters tab. Data is not displayed, since you have not yet configured Unravel to monitor your workspaces.
Configure Unravel for Azure Databricks workspaces so Unravel can connect and deploy Unravel agent binaries. You can configure multiple workspaces.
Navigate to Workspace > User Settings > Access Tokens and click Generate New Token. Leave the token lifespan as
unspecified, then the token lives indefinitely. Make note of the token's value to use in the next step.SSH to the Unravel VM and run the following to deploy Unravel agent binaries, etc. in the workspace. Also, update the Unravel server’s configuration with your workspace details.
/usr/local/unravel/install_bin/databricks_setup.sh --add-workspace -i
<Workspace>-n<Workspace Name>-t<Workspace Token>-r<Workspace Url>-u<Unravel VM Private IP>:4043 -p premium
Restart Unravel.
service unravel_all.sh restart
You must configure Azure Databricks for each task type you want Unravel to monitor.
Important
You must complete steps 1 and 2 for all task types. The remaining steps need to completed for the specific task types.
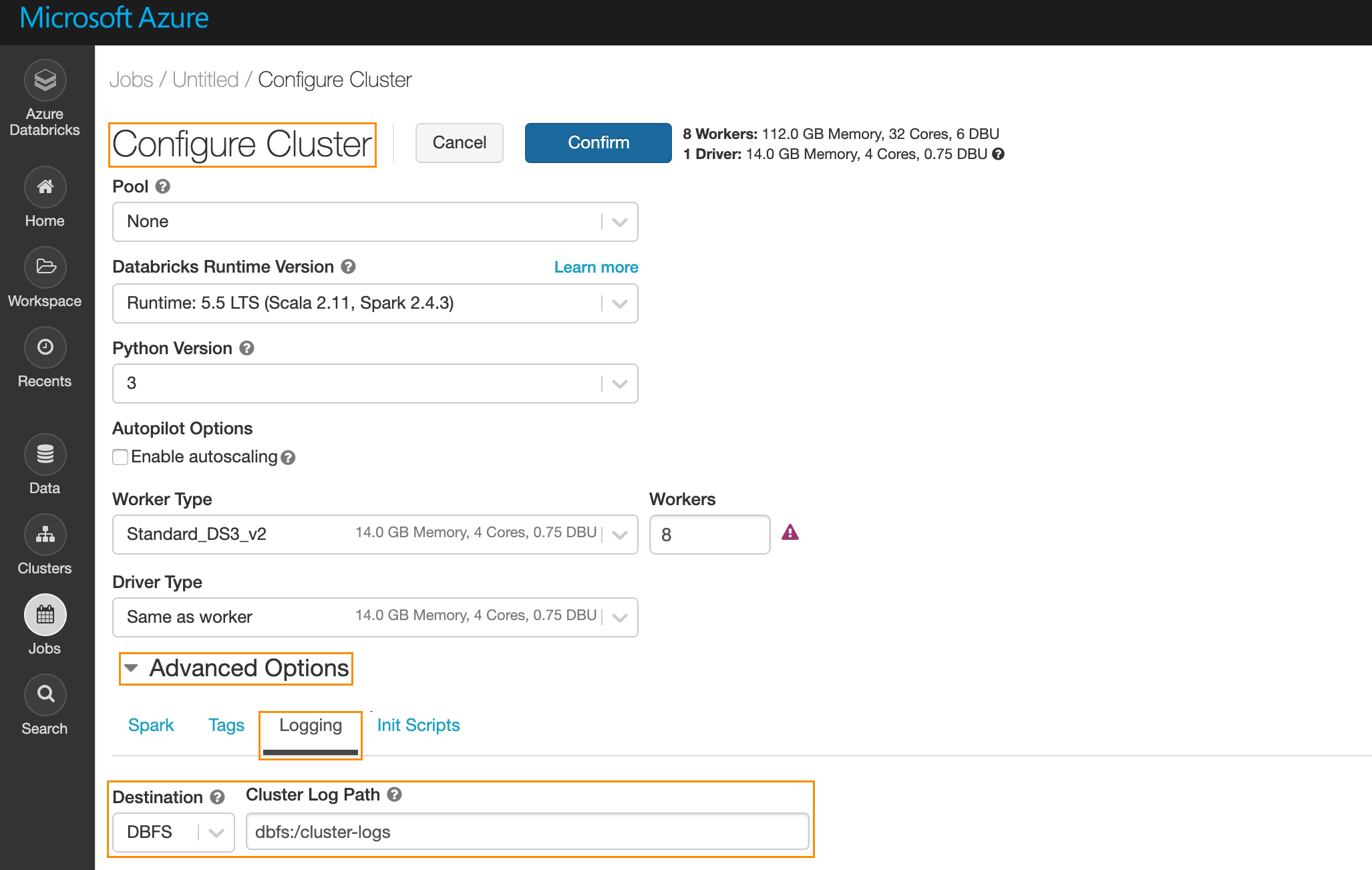
Specify the log path,
dbfs:/cluster-logs.UI
In the Azure portal navigate to Job > Configure Cluster. Under Advanced Options ,click Logging. Enter the following information.
Destination: Select
DBFS.CLuster Log Path: Enter
dbfs:/cluster-logs.
Specify cluster init script.
UI
Under Advanced Options, click Init Scripts to enter the following information.
Type: Select
DBFS.Custer Log Path: Enter
dbfs:/databricks/unravel/unravel-db-sensor-archive/dbin/install-unravel.sh.
For Notebook, Python, and Jar task types add the following Spark Configuration.
UI
Under Advanced Options click Spark then Spark Config and enter the following:
spark.executor.extraJavaOptions -Dcom.unraveldata.client.rest.request.timeout.ms=1000 -Dcom.unraveldata.client.rest.conn.timeout.ms=1000 -javaagent:/dbfs/databricks/unravel/unravel-agent-pack-bin/btrace-agent.jar=config=executor,libs=spark-2.4 spark.eventLog.enabled true spark.unravel.server.hostport
<Unravel VM Private IP Address>:4043 spark.driver.extraJavaOptions -Dcom.unraveldata.client.rest.request.timeout.ms=1000 -Dcom.unraveldata.client.rest.conn.timeout.ms=1000 -javaagent:/dbfs/databricks/unravel/unravel-agent-pack-bin/btrace-agent.jar=config=driver,script=StreamingProbe.btclass,libs=spark-2.4 spark.eventLog.dir dbfs:/databricks/unravel/eventLogs/ spark.unravel.shutdown.delay.ms 300
For spark-submit task types, add the following Spark configuration.
UI
Under Advanced Options, click Spark then Spark Config Configure spark-submit. Add the following along with the rest of the task parameters
"--conf", "spark.executor.extraJavaOptions= -Dcom.unraveldata.client.rest.request.timeout.ms=1000 -Dcom.unraveldata.client.rest.conn.timeout.ms=1000 -javaagent:/dbfs/databricks/unravel/unravel-agent-pack-bin/btrace-agent.jar=config=executor,libs=spark-2.4", "--conf", "spark.eventLog.enabled=true", "--conf", "spark.unravel.server.hostport=
<Unravel VM Private IP Address>:4043", "--conf", "spark.driver.extraJavaOptions= -Dcom.unraveldata.client.rest.request.timeout.ms=1000 -Dcom.unraveldata.client.rest.conn.timeout.ms=1000 -javaagent:/dbfs/databricks/unravel/unravel-agent-pack-bin/btrace-agent.jar=config=driver,script=StreamingProbe.btclass,libs=spark-2.4", "--conf", "spark.eventLog.dir=dbfs:/databricks/unravel/eventLogs/", "--conf", "spark.unravel.shutdown.delay.ms=300"
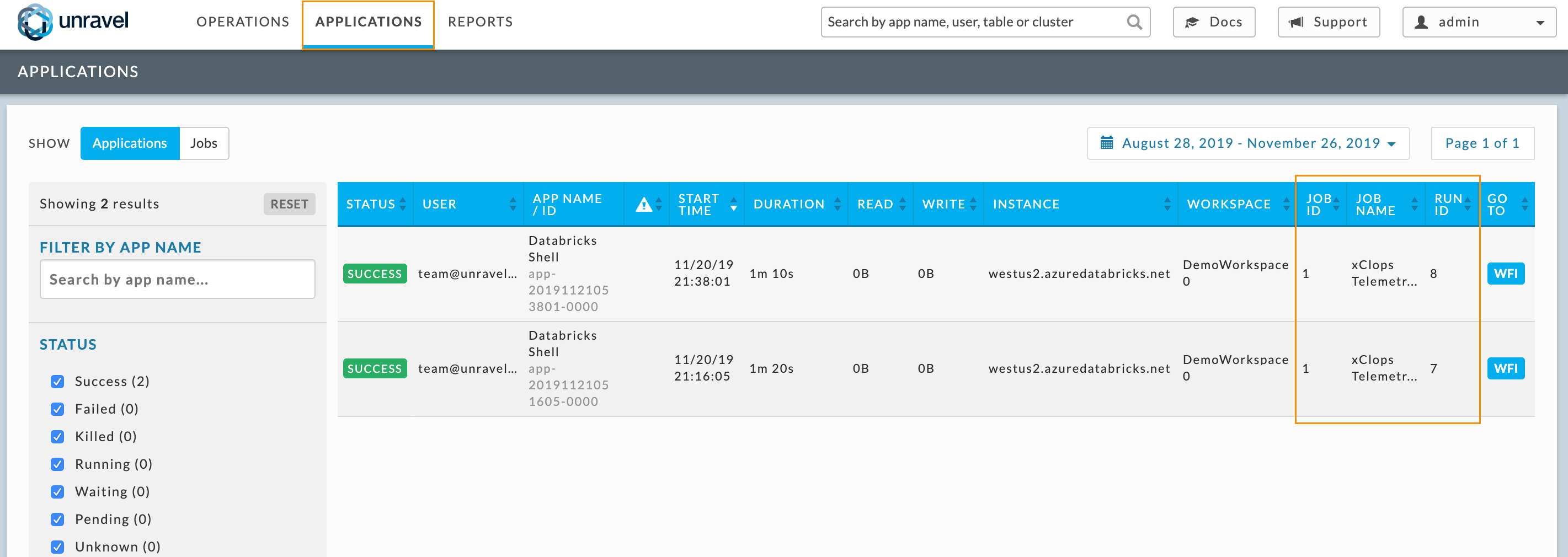
After you have configured a job with Unravel (Step 3 ), the corresponding job run is listed in the Unravel UI. Log into the Unravel server via a web browser. Enter either http:// <hostname or IP of the VM>:3000. Log in using the Admin username and password entered in the VM Parameters tab.