Running verification scripts and benchmarks
This topic explains how to run verification tests and benchmarks after you install or upgrade Unravel Server.
Why run verification tests or benchmarks?
Verification tests highlight the value of Unravel’s application performance management/analysis.
Benchmarks verify that Unravel features are working correctly.
Running verification tests
Unravel provides verification tests for Spark jobs only. Follow the instructions in the section that matches your deployment.
Running benchmarks
We provide sample Spark apps that you can download from the Unraveldata website. These apps are useful for verifying that an upgrade is successful. Please follow the instructions below for the app you want.
Spark
Package name | Location |
|---|---|
Benchmarks 1.6.x | |
Benchmarks 2.0.x |
The .tgz file includes everything needed to run the benchmarks including both the datasets and scripts.
Go to the directory where you want to download and unpack the benchmark package. Download the file, where
locationis full pathname of the benchmark (see above) andpackage-nameis the package name.curl
location-opackage-nameOnce downloaded, run md5sum on
package-nameto ensure it's intact.md5sum
package-nameConfirm that the output of md5sum is exactly as shown below for the package you just unpacked.
ff8e56b4d5abfb0fb9f9e4a624eeb771 Md5sum for spark-benchmarks1.tgz 71198901cedeadd7f8ebcf1bb1fd9779 Md5sum for demo-benchmarks-for-spark-2.0.tgz
Uncompress the package.
tar -zxvf
package-nameAfter unpacking, navigate to the created directory,
demo_dir.cd
demo_dirls benchmarks/ data/The benchmarks folder includes the jar of the Spark examples, the source files, and the scripts used to execute the examples.
ls benchmarks README recommendations.png src/ lib/ scripts/ tpch-query-instances/
libcontains compiled jar of all examples.scriptscontain all the scripts needed to run the example. There are two scripts for each example:./example*.shis the initial execution and./example*-after.shis the re-execution of the same example after applying Unravel’s recommendations:srccontains the source files for the driver program.tpch-query-instancescontains the queries for a TPC-H benchmark.
Navigate to the data folder which contains the datasets used by the examples.
cd data ls data DATA.BIG.2G/ tpch10g/
Upload the datasets (requiring 12 GB size)
hdfs dfs -put tpch10g/ /tmp/ hdfs dfs -put DATA.BIG.2G/ /tmp/
Execute the first benchmark script, where
script-numberis the number of the script you wish to execute../example
script-number.shAfter the run, Unravel recommendations are shown in the UI, on the application page. Once the example script is issued, the application metadata is displayed. Use the
app idlisted in the metadata to locate the app in Unravel UI.Recommendations are deployment specific so you need to edit the Spark properties in the example
script-number-after.shThe categories of recommendations and insights are:
actionable recommendations (examples 1, 2 , and 5)*
Spark SQL (example 3)
error view and insights for failed applications (example4) and
recommendations for caching (example 5)
*if running Benchmarks 2.0.x, example 6 is an actionable recommendation.
Sample Spark recommendations
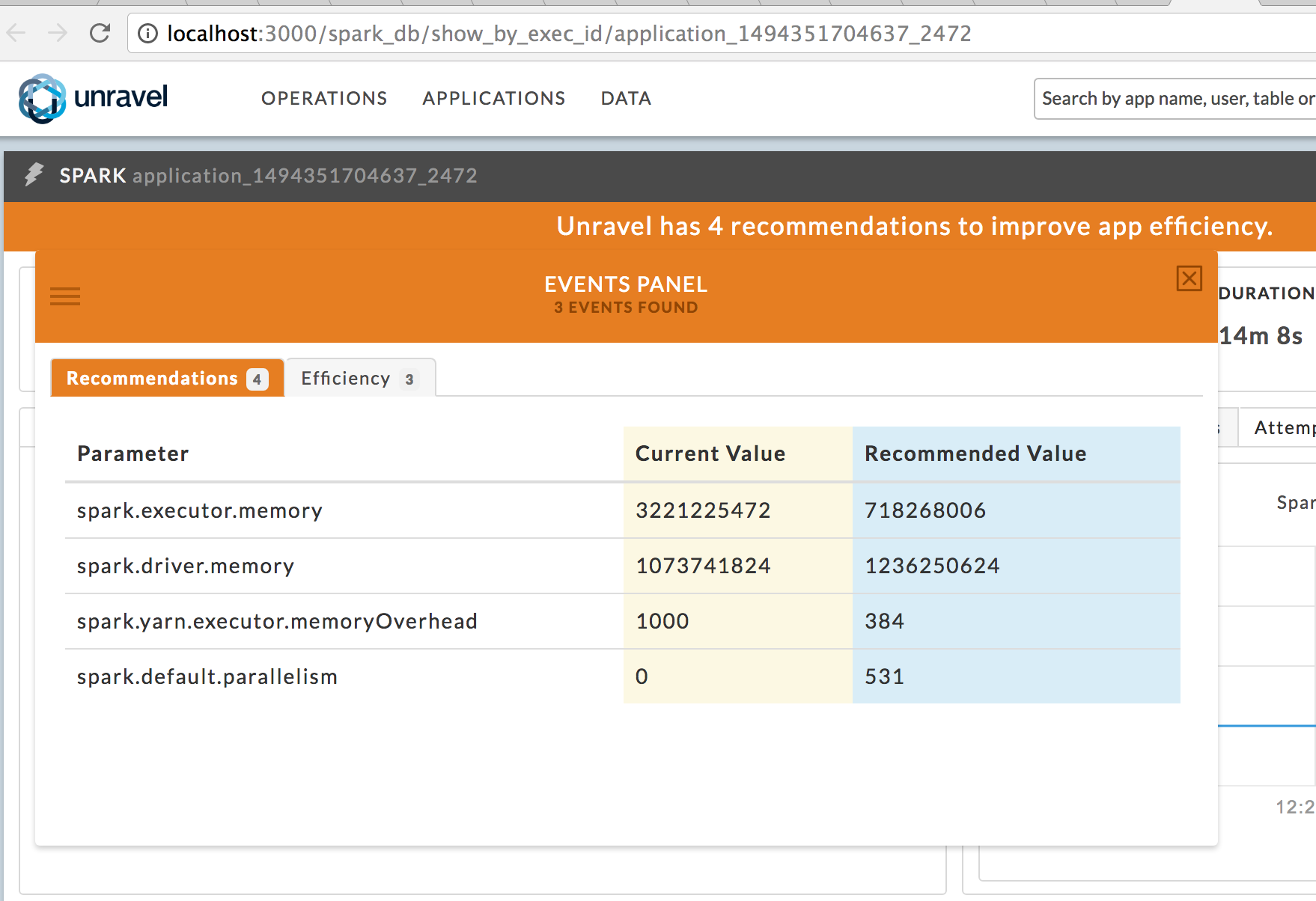
Execute the edited
*-afterscript, that includes the Spark configuration properties as suggested in the Recommendations tab of the Unravel UI.$ ./example
$-after.shAfter you install, after running the sample, check whether the re-execution of the script improved the performance or resource efficiency of the application. You can also check the Program and the Execution Graph tabs in Unravel UI. Click an RDD in the Execution Graph to see the corresponding line of code in the app.
Example 5
To run this script you must enable insights for caching, which are disabled by default as it consumes an additional heap from the memory allocation of the Spark worker daemon. You should enable insights for caching only if you expect that caching will improve the performance of your Spark application.
Add the following property to
/usr/local/unravel/etc/unravel.propertieson the Unravel server node:com.unraveldata.spark.events.enableCaching=true
Restart the spark worker daemon.
sudo /etc/init.d/unravel_sw_1 restart
Repeat step 9 - 12.
Once you have completed running
example5.shandexample5-after.sh, reset the caching insight option to false.com.unraveldata.spark.events.enableCaching=false
Restart the spark worker daemon.
$ sudo /etc/init.d/unravel_sw_1 restart
Description | Demonstrates |
|---|---|
example1 A Scala-based application that generates its input and applies multiple transformations to the generated data. | How Unravel helps select the number of partitions and container sizes for best performance, e.g., increasing the number of partitions and reducing per-container memory resources. |
example2 A Scala-based application that generates its input and applies multiple transformations to the generated data. | How Unravel helps select the container sizes for best performance, in other words, reducing per-container memory resources. |
example3 A Scala program containing a SparkSQL query. The program runs TPC-H Query #9 on a 10GB database. | How Unravel helps select the number of executors for best performance when dynamic allocation is disabled. For example, increasing the number of executors. |
example4 A Scala-based application. This application generates its input and applies multiple transformations to the generated data. | How Unravel helps to root-cause a failed application. For example, failure-related insights and Error View when the application runs out of memory. |
example5 A Scala-based application. The application runs on an input of 2GB and applies multiple join and co-group transformations on the input data. Certain RDDs are evaluated multiple times. Pre-requirement: Add the property com.unraveldata.spark.events.enableCaching=true to This property is disabled by default as it consumes additional heap from the memory allocation of the Spark worker daemon. Enable it only if caching-related insights are considered for tuning the performance of Spark applications. | Unravel’s insights for caching by showing the caching opportunities within the application, i.e., where in the program to use persist() to cache the corresponding RDD. In this example, dynamic allocation is disabled. |
Example | Demonstrates |
|---|---|
example1 see example1 in Benchmarks for Spark 1.6.x | |
example2 A Scala-based application that generates its input and applies multiple transformations to the generated data including the coalesce transformation, which reduces the level of parallelism to a suboptimal value. | How Unravel helps select the number of partitions and container sizes for the best performance of a Spark application. For example, by increasing the number of partitions. |
example3 - example5 see example3 - example5 in Benchmarks for Spark 1.6.x | |
example6 A Scala-based Spark application that generates its input and applies multiple transformations to the generated data. | How Unravel helps select the container sizes for best performance of a Spark application, e.g., reducing the memory requirements per executor. |