Part 2: Enabling additional instrumentation
This topic explains how to configure Unravel to retrieve additional data from Hive, Tez, Spark and Oozie, such as Hive queries, application timelines, Spark jobs, YARN resource management data, and logs. You'll do this by generating Unravel's JARs and distributing them to every node that runs queries in the cluster. Later, after JARs are distributed to the nodes, you'll integrate Hive, Tez, and Spark data with Unravel.
1. Generate and distribute Unravel's Hive Hook and Spark Sensor JARs
2. Configure Ambari to work with Unravel
Hive configurations
Hive
Click Hive > Configs > Advanced > Advanced hive-env. In the hive-env template, towards the end of line, add:
export AUX_CLASSPATH=${AUX_CLASSPATH}:/usr/local/unravel-jars/unravel-hive-1.2.0-hook.jar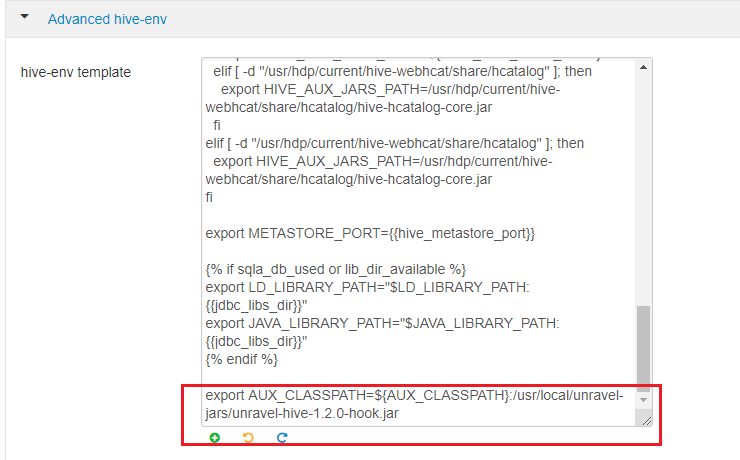
Hive Hook
In Ambari's general properties, append
,com.unraveldata.dataflow.hive.hook.UnravelHiveHook, to the following properties:Important
Be sure to append with no space before or after the comma, for example, property=existingValue,newValue
hive.exec.failure.hooks hive.exec.post.hooks hive.exec.pre.hooks For example, com.unraveldata.dataflow.hive.hook.UnravelHiveHook
hive.exec.failure.hooks=
existing-value,com.unraveldata.dataflow.hive.hook.UnravelHiveHook hive.exec.post.hooks=existing-value,com.unraveldata.dataflow.hive.hook.UnravelHiveHook hive.exec.pre.hooks=existing-value,com.unraveldata.dataflow.hive.hook.UnravelHiveHook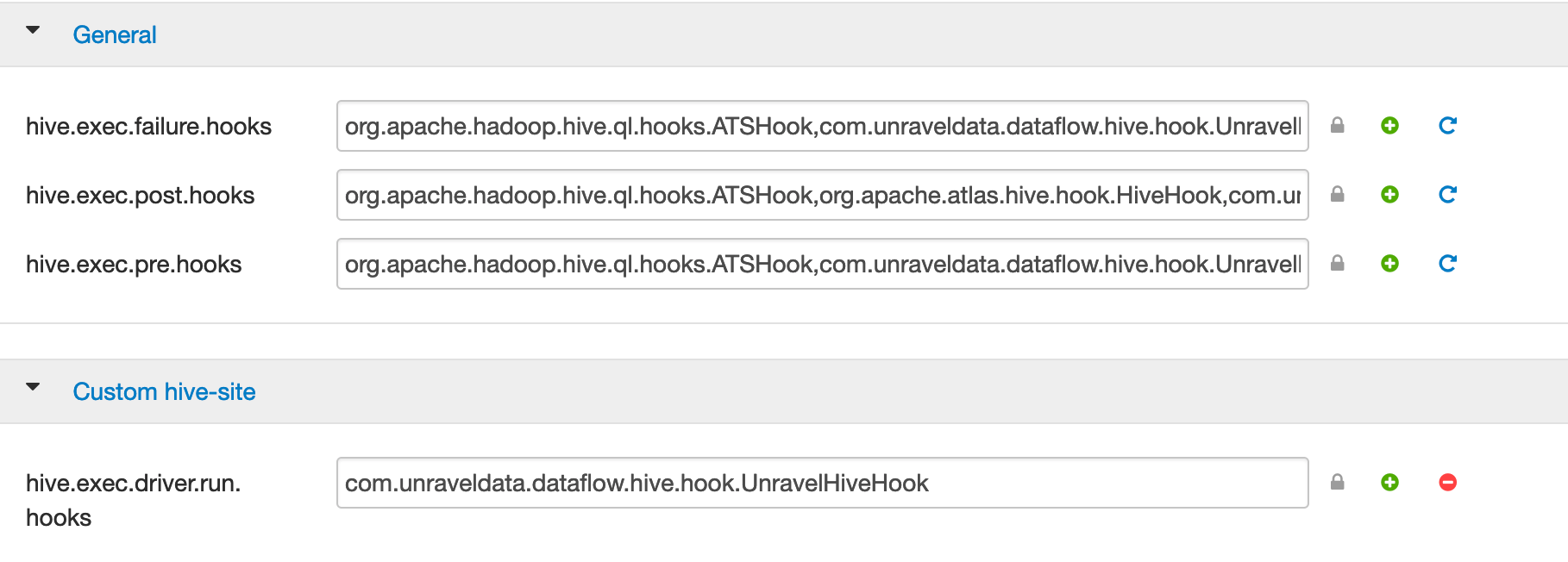
Custom
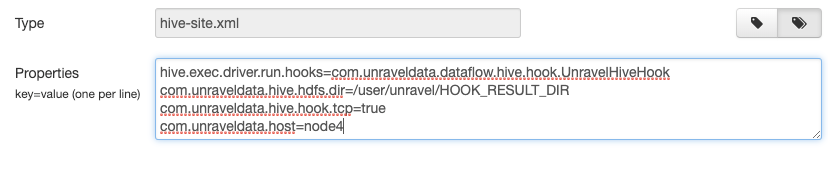
In Ambari's custom hive-site editor set com.unraveldata.host: to
unravel-gateway-internal-IP-hostnameFor example,
Optional: Hive LLAP if it is enabled
Tip
Edit
hive-site.xmlmanually, not through Ambari Web UI.Copy the settings in Custom hive-interactive-site and paste them into
/etc/hive/conf/hive-site.xml.Copy the settings in Advanced hive-interactive-env and paste them into
/etc/hive/conf/hive-site.xml.
Notice
If you have an Unravel version older than 4.5.1.0, create HDFS Hive Hook directories for Unravel:
hdfs dfs -mkdir -p /user/unravel/HOOK_RESULT_DIR hdfs dfs -chown unravel:hadoop /user/unravel/HOOK_RESULT_DIR hdfs dfs -chmod -R 777 /user/unravel/HOOK_RESULT_DIR
Configure HDFS.
Click HDFS > Configs > Advanced > Advanced hadoop-env. In the hadoop-env template, look for export HADOOP_CLASSPATH and append Unravel's JAR path as shown.
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:/usr/local/unravel-jars/unravel-hive-1.2.0-hook.jar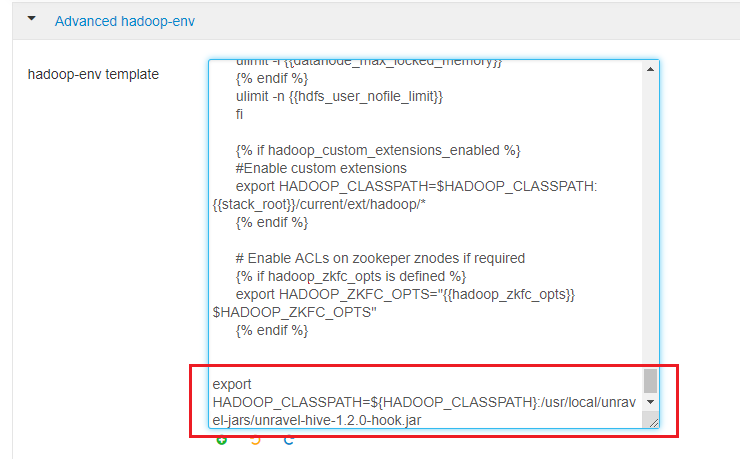
Configure the BTrace agent for Tez
In the
tez-site.xmlconfiguration file, append the following Java options to tez.am.launch.cmd-opts and tez.task.launch.cmd-opts:-javaagent:/usr/local/unravel-jars/btrace-agent.jar=libs=mr,config=tez -Dunravel.server.hostport=
unravel-host:4043Tip
In a Kerberos environment you need to modify tez.am.view-acls property with the "run as" user or *.
Configure the Application Timeline Server (ATS).
Note
From Unravel v4.6.1.6, this step is not mandatory.
In
yarn-site.xml:yarn.timeline-service.enabled=true yarn.timeline-service.entity-group-fs-store.group-id-plugin-classes=org.apache.tez.dag.history.logging.ats.TimelineCachePluginImpl yarn.timeline-service.version=1.5 or yarn.timeline-service.versions=1.5f,2.0f
If yarn.acl.enable is
true, addunravelto yarn.admin.acl.In
hive-env.sh, add:Use ATS Logging: true
In
tez-site.xml, add:tez.dag.history.logging.enabled=true tez.am.history.logging.enabled=true tez.history.logging.service.class=org.apache.tez.dag.history.logging.ats.ATSV15HistoryLoggingService tez.am.view-acls=
unravel-"run-as"-user or *Note
From HDP version 3.1.0 onwards, this Tez configuration must be done manually.
Configure Spark-on-Yarn
Tip
For
unravel-host, use Unravel Server's fully qualified domain name (FQDN) or IP address.Add the location of the the Spark JARs.
Click Spark > Configs > Custom spark-defaults > Add Property and use
 Bulk property add mode, or edit
Bulk property add mode, or edit spark-defaults.confas follows:Tip
If your cluster has only one Spark 1.X version,
spark-defaults.confis in/usr/hdp/current/spark-client/conf.If your cluster is running Spark 2.X,
spark-defaults.confis in/usr/hdp/current/spark2-client/conf.
This example uses default locations for Spark JARs. Your environment may vary.
spark.unravel.server.hostport=
unravel-host:4043 spark.driver.extraJavaOptions=-javaagent:/usr/local/unravel-jars/btrace-agent.jar=config=driver,libs=spark-versionspark.executor.extraJavaOptions=-javaagent:/usr/local/unravel-jars/btrace-agent.jar=config=executor,libs=spark-versionspark.eventLog.enabled=true
Configure Oozie
3. Configure the Unravel Host
Define the following properties in /usr/local/unravel/etc/unravel.properties. If you do not find the properties add them.
Tez.
Set these if the Application Timeline Server (ATS) requires authentication.
4. Optional: Confirm that Unravel UI shows Tez data.
Run
/usr/local/unravel/install_bin/hive_test_simple.shon the HDP cluster or on any cloud environment wherehive.execution.engine=tez.Log into Unravel server and go to the Applications page. Check for Tez jobs.
Unravel UI may take a few seconds to load Tez data.